AutoML with TPOT. A Genetic Programming Approach via TPOT For ML Automation in 2 lines

What is Auto ML?
Automated Machine Learning (Auto ML) in brief refers to the automation of the whole machine learning process to find the best-suited model for prediction.
The below figure shows how Tpot Works:
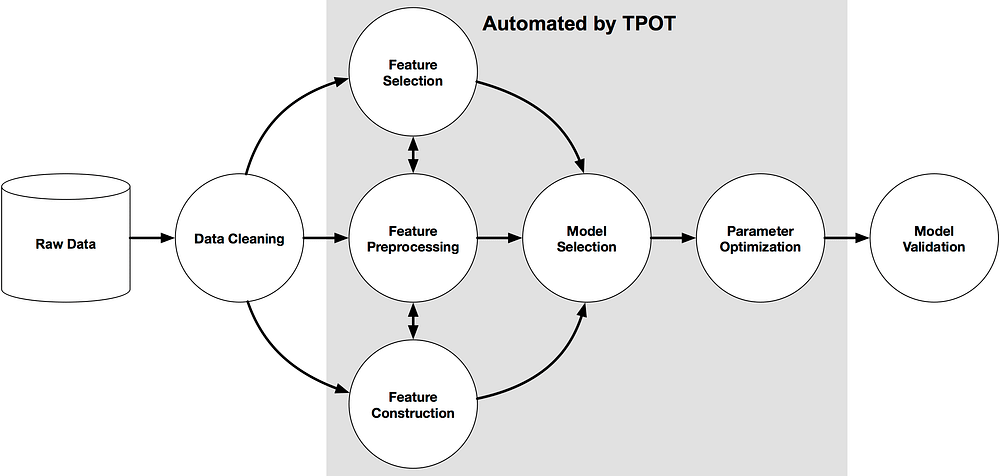
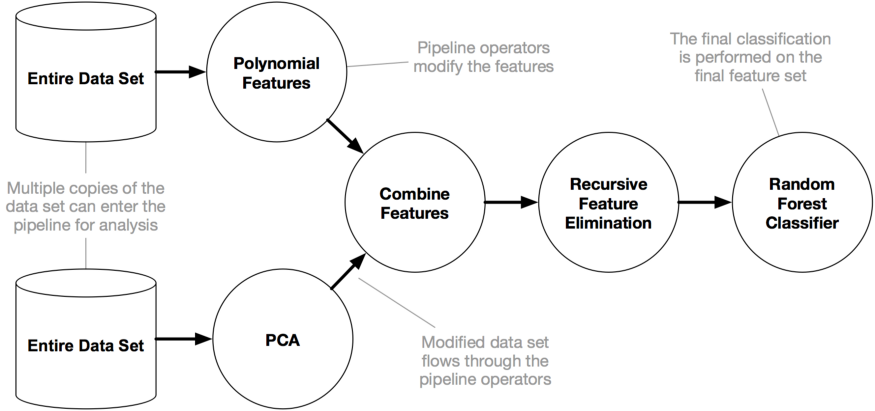
TPOT is built on top of scikit-learn and is still under active development.
To use the TPOT we need to use ‘ pip install tpot’
from tpot import TPOTClassifier
from tpot import TPOTRegressor
model = TPOTClassifier(generations=100, population_size=100, offspring_size=None, mutation_rate=0.9, crossover_rate=0.1, scoring=None, cv=5, subsample=1.0, n_jobs=1, max_time_mins=None, max_eval_time_mins=5, random_state=None, config_dict=None, template=None, warm_start=False, memory=None, use_dask=False, periodic_checkpoint_folder=None, early_stop=None, verbosity=0, disable_update_check=False, log_file=None)
here is the list of default parameters
generations=100,
population_size=100,
offspring_size=None # Jeff notes this gets set to population_size
mutation_rate=0.9,
crossover_rate=0.1,
scoring="Accuracy", # for Classification
cv=5,
subsample=1.0,
n_jobs=1,
max_time_mins=None,
max_eval_time_mins=5,
random_state=None,
config_dict=None,
warm_start=False,
memory=None,
periodic_checkpoint_folder=None,
early_stop=None
verbosity=0
disable_update_check=False
The description of each parameter defined in detail @ the official Tpot http://epistasislab.github.io/tpot/
As of now, let's consider a few of the important most uses parameters.
‘generations = 5’ as an evolution algorithm, involves setting configuration, such as the size of
- generations: Number of iterations to the run pipeline optimization process. The default is 100.
- population_size: Number of individuals to retain in the genetic programming population every generation. The default is 100.
- offspring_size: Number of offspring to produce in each genetic programming generation. The default is 100.
- mutation_rate: Mutation rate for the genetic programming algorithm in the range [0.0, 1.0]. This parameter tells the GP algorithm how many pipelines to apply random changes to every generation. Default is 0.9
- crossover_rate: Crossover rate for the genetic programming algorithm in the range [0.0, 1.0]. This parameter tells the genetic programming algorithm how many pipelines to “breed” every generation.
- scoring: Function used to evaluate the quality of a given pipeline for the classification problem like
accuracy,average_precision,roc_auc,recall, etc. The default isaccuracy. - cv: Cross-validation strategy used when evaluating pipelines. The default is 5.
- random_state: The seed of the pseudo-random number generator used in TPOT. Use this parameter to make sure that TPOT will give you the same results each time you run it against the same data set with that seed.
- n_jobs = -1 if you which to run on multiple cpu cores to speed up the tpot process.
- periodic_checkpoint_folder = “any_string” so that we can watch the models evolve while the training scores improve.
Also note mutation_rate + crossover_rate cannot exceed 1.0.
Now let’s get hands-on experience on how we can apply in our day-to-day data science jobs.
from pandas import read_csv
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import RepeatedStratifiedKFold
from tpot import TPOTClassifier
dataframe = read_csv('sonar.csv')#define X and y
data = dataframe.values
X, y = data[:, :-1], data[:, -1]
# minimally prepare dataset
X = X.astype('float32')
y = LabelEncoder().fit_transform(y.astype('str'))
#split the dataset
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
# define cross validation
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
Now we will run the TPOTClassifier
#initialize the classifier
model = TPOTClassifier(generations=5, population_size=50,max_time_mins= 2,cv=cv, scoring='accuracy', verbosity=2, random_state=1, n_jobs=-1)
model.fit(X_train, y_train)
#export the best model
model.export('tpot_best_model.py')
This will save our model pipelines in a .py file later for us to import. However, one thing you might notice the generations, population_size, max_time_mins I kept it minimum for these use cases. Else it takes time is one of the limitations of tpot.
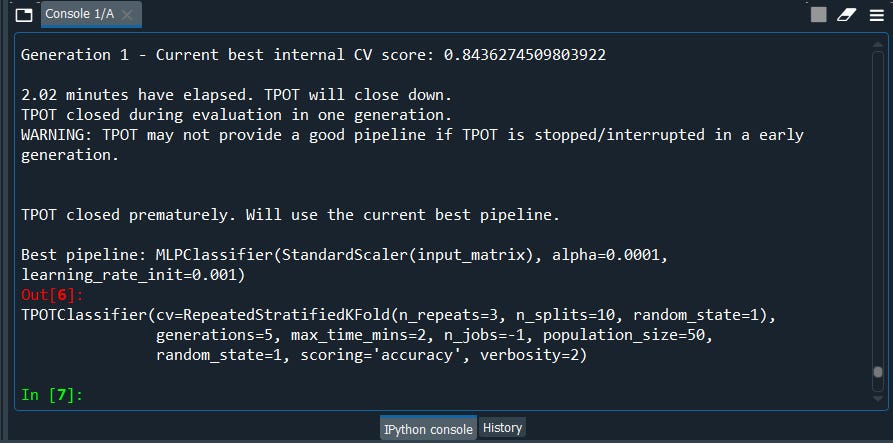
Here we are opening the file tpot_best_model.py and we have everything set ready to go …
import numpy as np
import pandas as pd
from sklearn.linear_model import RidgeCV
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures
from tpot.export_utils import set_param_recursive
# NOTE: Make sure that the outcome column is labeled 'target' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = tpot_data.drop('target', axis=1)
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['target'], random_state=1)
# Average CV score on the training set was: -29.099695845082277
exported_pipeline = make_pipeline(
PolynomialFeatures(degree=2, include_bias=False, interaction_only=False),
RidgeCV()
)
# Fix random state for all the steps in exported pipeline
set_param_recursive(exported_pipeline.steps, 'random_state', 1)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)
In case if you wanna do the prediction
yhat = exported_pipeline.predict(new_data)
Now let’s see how can we do the same with Regressor
from pandas import read_csv
from sklearn.model_selection import RepeatedKFold
from tpot import TPOTRegressor
# load dataset
dataframe = read_csv(auto-insurnace)
#define X and y
data = dataframe.values
data = data.astype('float32')
X, y = data[:, :-1], data[:, -1]
#define the cross validation
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
Now we will run the TPOTRegressor
# define search
model = TPOTRegressor(generations=5, population_size=50, scoring='neg_mean_absolute_error', cv=cv, verbosity=2, random_state=1, n_jobs=-1)
model.fit(X, y)
#export the best model
model.export('tpot_insurance_best_model.py')
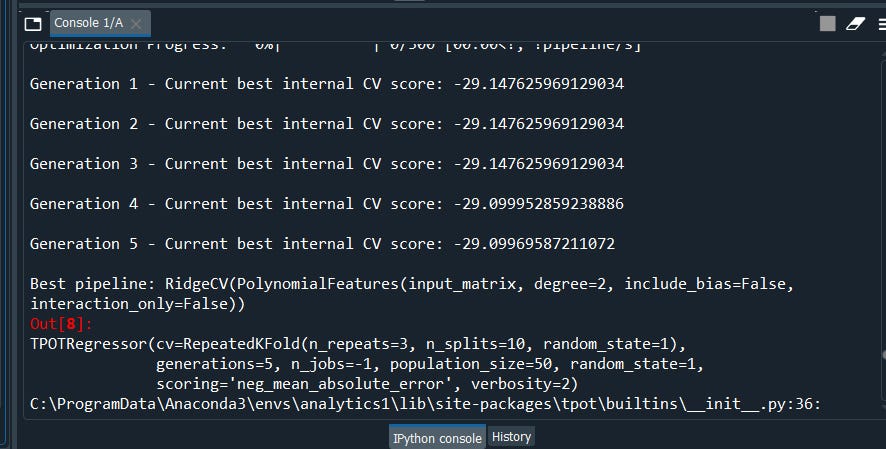
Now again if we open the .py file we will have our optimized code ready to go.
import numpy as np
import pandas as pd
from sklearn.linear_model import RidgeCV
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures
from tpot.export_utils import set_param_recursive
# NOTE: Make sure that the outcome column is labeled 'target' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = tpot_data.drop('target', axis=1)
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['target'], random_state=1)
# Average CV score on the training set was: -29.099695845082277
exported_pipeline = make_pipeline(
PolynomialFeatures(degree=2, include_bias=False, interaction_only=False),
RidgeCV()
)
# Fix random state for all the steps in exported pipeline
set_param_recursive(exported_pipeline.steps, 'random_state', 1)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)
Tpot is considered to be a Genetic Programming to solve the challenging problem of finding the best model. Genetic algorithms are inspired by the Darwinian process of Natural Selection and been used in computer science to find the optimized search.
In brief Genetic Algorithm consists of 3 common behaviors.
- Selection
- Crossover
- Mutation
Did you enjoyed it? if so let me know…….do browse my other articles i guarantee you will like them too. See you soon with another interesting topic.
Some of my alternative internet presences are Facebook, Instagram, Udemy, Blogger, Issuu, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Have a good day.



Comments
Post a Comment