Near Miss — under sampling

As discussed in our previous articles
1.) SMOTE Over-sampling
2.) Borderline SMOTE
a. ) Borderline SMOTE KNN
b. ) Borderline SMOTE SVM
3.) Adaptive Synthetic Sampling (ADASYN)
Here is the link https://medium.com/data2dimensions-rupak-bob-roy/borderline-knn-svm-and-adaysn-smote-57a8a6bb39c
In this short article, we will discuss another alternative to SMOTE- oversampling called as NearMiss Algorithm- under sampling
NearMiss — under sampling
As the name says it's an under-sampling technique that aims to balance the class distribution by eliminating the majority class samples just like in SMOTE oversampling.
Here too it uses near-neighbor methods to reduce the majority class sample.
Let me explain you with the help of an example
#Frist we will build a baseline model for comparison
# import necessary modules
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, classification_report
# load the data set
data = pd.read_csv('creditcard.csv')
X = data.drop("Class",axis=1)
y = data["Class"]# as you can see there are 492 fraud transactions.
data['Class'].value_counts()
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 0)
# logistic regression object
lr = LogisticRegression()
lr.fit(X_train, y_train.ravel())
predictions = lr.predict(X_test)
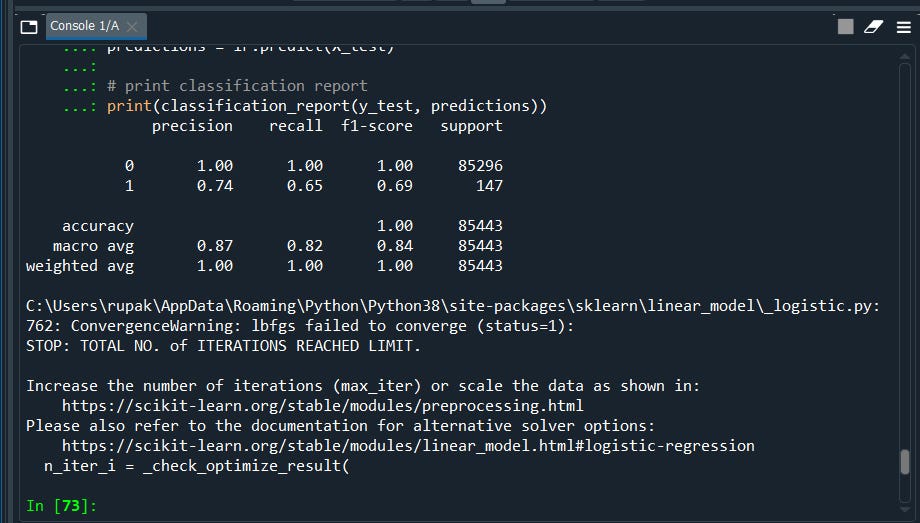
#print classification report
print(classification_report(y_test, predictions))
Now re-run the model with NearMiss undersampling
print("Before Under Sampling, counts of label '1': {}".format(sum(y_train == 1)))
print("Before Under Sampling, counts of label '0': {} \n".format(sum(y_train == 0)))Before Under Sampling, counts of label ‘1’: 345
Before Under Sampling, counts of label ‘0’: 199019
#pip install imbalanced-learn
# apply near miss
from imblearn.under_sampling import NearMiss
nr = NearMiss(sampling_strategy="auto")
X_train_miss, y_train_miss = nr.fit_resample(X_train, y_train.ravel())
print("After Undersampling, counts of label '1': {}".format(sum(y_train_miss == 1)))
print("After Undersampling, counts of label '0': {}".format(sum(y_train_miss == 0)))After Undersampling, counts of label ‘1’: 345
After Undersampling, counts of label ‘0’: 345
Here we go! we have our classes balanced.
Let’s check its accuracy
#train the model with the balanced dataset
lr2 = LogisticRegression()
lr2.fit(X_train_miss, y_train_miss.ravel())
predictions = lr2.predict(X_test)
# print classification report
print(classification_report(y_test, predictions))
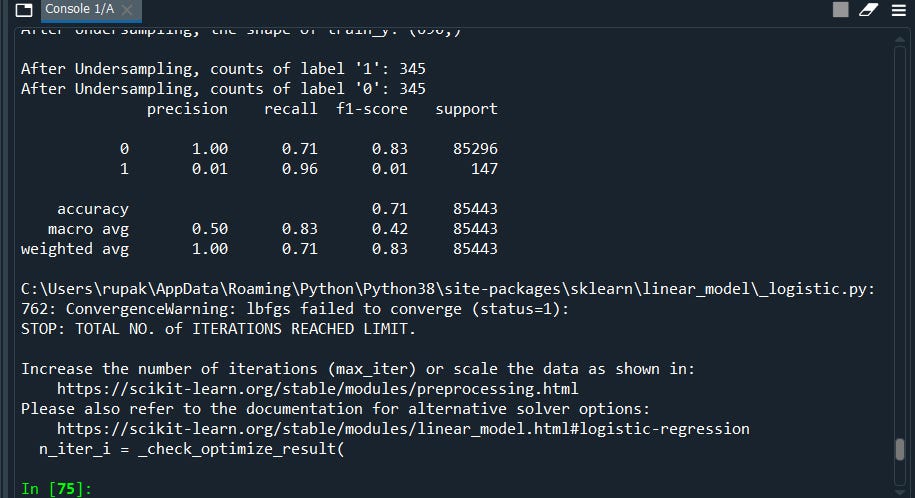
Notice, we have now better recall accuracy from our previous model. Thus this is a good model as compared to our previous model.
Finally, we went through the 4 types of Synthetic Data Resampling techniques. I hope you enjoyed it, if you are interested to know more about the other variants you can follow my profile stories.
See you soon with another cool topic.
If you like to know more about advanced topics like clustering follow my other article ‘A-Z clustering’
Some of my alternative internet presences Facebook, Instagram, Udemy, Blogger, Issuu, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Have a good day.



Comments
Post a Comment