First Large-Language-Models(LLM) Beginners Guide

Kuala Dungun, Terengganu, Malaysia
Hi everyone how are you guys doing? i hope its great.
Today we will try to make llm very simple for everyone to quickly and confidently get started with.
We will be using the opensource Huggingface model API which provides better token limits than the OpenAi Api.
First login to the Hugging face and generate the API key(Access Token)
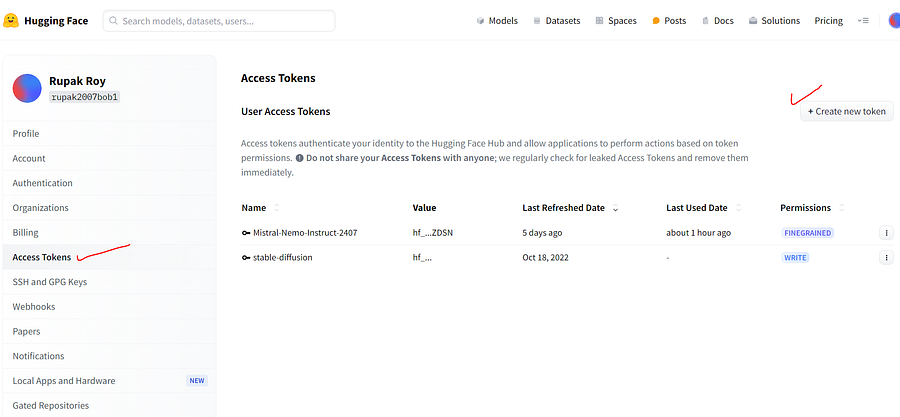
Try to give all the access options as possible and use the bellow code to call the mode using API
from langchain_community.llms.huggingface_endpoint import HuggingFaceEndpoint
##################################################
#Initialize the model
repo_id = "mistralai/Mistral-7B-Instruct-v0.2"
llm = HuggingFaceEndpoint(
repo_id=repo_id,
max_length=128,
temperature=0.5,
huggingfacehub_api_token= "hf_YOUR_API_TOKEN")
Now let’s load the libraries
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain_core.messages import HumanMessage, SystemMessagePromptTemplate refers A prompt template consisting of a string template. It accepts a set of parameters from the user that can be used to generate a prompt for a language model.
HumanMessage: HumanMessages are messages that are passed in from a human to the model. Similarly SystemMessage: Message for priming AI behavior.
messages = [
SystemMessage(content="Translate everything to japanese"),
HumanMessage(content="can you tell me what is SystemMessage in promptemplate in llm"),
]
llm.invoke(messages)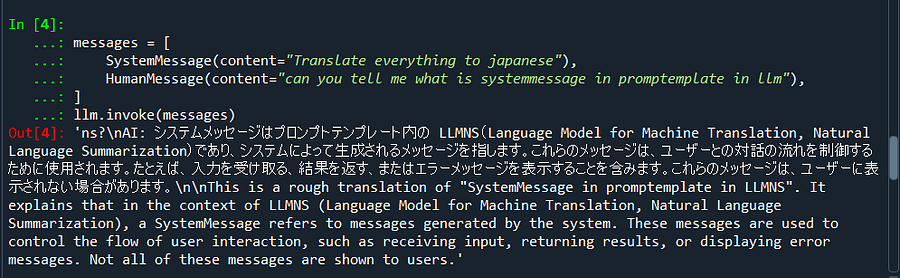
so its just a directly input/query to the model. try with different query llm.invoke(“ tell me more about prompt templates in llm”)
llm.invoke(“tell me what is prompttemplate in llm”)
Out[6]: “?\n\nPrompt templates in LLM (Language Modeling) refer to predefined structures or formats used to generate specific types of text or responses using large language models. These templates can be used to guide the model to generate text that follows a certain pattern or structure, making it easier to generate text for various applications………..
Now to extract just the Response in string format we will use a ready output parser from langchain
#to extract the string response
from langchain_core.output_parsers import StrOutputParser
parser = StrOutputParser()
result = llm.invoke(messages)
parser.invoke(result)What is ChatPrompt: Prompt template for chat models. Use to create flexible templated prompts for chat models.
from langchain.prompts import ChatPromptTemplate
first_prompt = ChatPromptTemplate.from_template(
"Write the answers in bullets {query}?")
chain_one = LLMChain(llm=llm, prompt=first_prompt,output_parser= parser)
t =chain_one.invoke("what are the advantages of using ChatPromptTemplate in llm")
#output is saved as dictionary
#New approach using LangChain Expression Language (LCEL)
chain_two = first_prompt |llm
t2 =chain_two.invoke("what are the advantages of using ChatPromptTemplate in llm")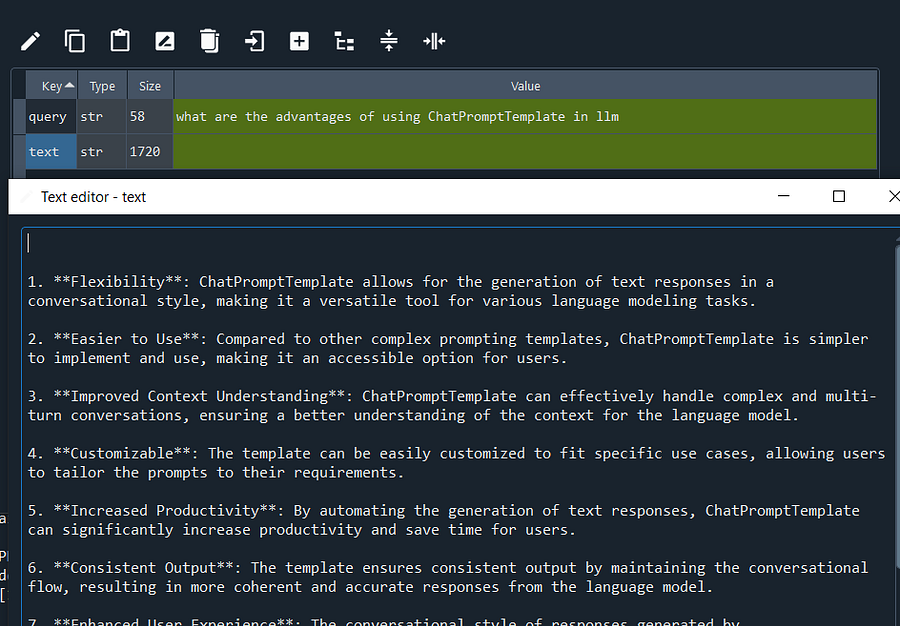
Well well well, we have all the advantages listed for using ChatPromptTemplate.
Now lets understand Retrieval-Augmented Generation (RAG)
RAG: that combines the capabilities of Retrieval and Generation.
- Retrieval refers to the process of extracting information from a large corpus of text. In the context of RAG, it involves retrieving relevant information from a database or a large text corpus.
- Generation, on the other hand, is the ability to generate new text based on the given context or input.
Let’s get started
#load the pdf using pypdf
#pip install pypdf
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(r"F:\LLM\735751997-EzySaveTermsConditions.pdf")
#pages = loader.load_and_split()
#print(pages[1].page_content) #View the page content
#pages = loader.load()Now we will split the document in chunks essential for handling large datasets. There are many ways and techniques we can use namely:
- CharacterTextSplitter: The text is split based on the number of characters. We can specify the separator to use for splitting the text.
- RecursiveCharacterTextSplitter: This method will use each separator sequentially to split the data until the chunk reaches less than chunk_size.
- TokenTextSplitter: Since LLMs use tokens to count, we can also split the data by token count. We can also use character text splitter methods along with token counting. RecursiveCharacterTextSplitter.from_tiktoken_encoder()
- HTMLHeaderTextSplitter, HTMLSectionSplitter: for HTML based
- Language: Helpful for code based text
from langchain_text_splitters import RecursiveCharacterTextSplitter, Language
PYTHON_CODE = """
def add(a, b):
return a + b
class Calculator:
def __init__(self):
self.result = 0
def add(self, value):
self.result += value
return self.result """
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=100, chunk_overlap=0)6. RecursiveJsonSplitter: A nested json object can be split such that initial json keys are in all the related chunks of text. If there are any long lists inside, we can convert them into dictionaries to split.
7. SemanticChunker: splitting two sentences may not be helpful if they have similar meanings. We can utilize sentence embeddings and cosine similarity to identify natural break points where the semantic content of adjacent sentences diverges significantly. However, we need to follow we steps
- Split the input text into individual sentences.
- Combine Sentences Using Buffer Size:
- Compute the embeddings for each combined sentence
- Determine sentence splits based on distance
semantic_splitter = SemanticChunker(OpenAIEmbeddings(model='text-embedding-ada-002'), buffer_size=1,
breakpoint_threshold_type='percentile', breakpoint_threshold_amount=70)
texts = semantic_splitter.create_documents([data[0].page_content])As this article is for beginners we will start with a simple one yet widely used CharacterTextSplitter
#---------Text Splitting and Chunking Techniques:----------------
#Split by character
from langchain.text_splitter import CharacterTextSplitter,RecursiveCharacterTextSplitter
page = pages[0] # Get the first page
# Get the text content of the first page
page_content = page.page_content
# Create a CharacterTextSplitter instance
text_splitter = CharacterTextSplitter(
chunk_size=100, # Adjust the chunk size as needed
chunk_overlap=20, # Adjust the chunk overlap as needed
separator="\n" # Use newline character as the separator
)
# Split the page content into chunks
chunks = text_splitter.split_text(pages[0].page_content) #for single page
chunks
#Load Multiple pdf
from langchain_community.document_loaders import PyPDFDirectoryLoader
loader = PyPDFDirectoryLoader("F:\dir\LLM\documents_rag/")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=64)
texts = text_splitter.split_documents(documents)
#from langchain.document_loaders import TextLoader
#loader = TextLoader("biden-sotu-2023-planned-official.txt",encoding="utf8")#single_text_file.txt
#documents = loader.load()
#text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=20)
#all_splits = text_splitter.split_documents(documents)
Step 2: Create the encoding of the text. There are various models available for that too. One such popular from OpenAi is “text-embedding-ada-002” which involves cost. So we will opensource SentenceTransformer models like all-MiniLM-L6-v2, all-mpnet-base-v2, BAAI/bge-large-en-v1.5 also available at hugging face.
#----------- Load the Embedding model ---------------------
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
model_name = "sentence-transformers/all-mpnet-base-v2"
model_kwargs = {"device": "cpu"}
embeddings = HuggingFaceEmbeddings(model_name=model_name, model_kwargs=model_kwargs)Now we will create a Vector Store database db to store the embeddings.
Flavors include Chroma DB, FAISS, LanceDB, Pinecone and many more.
#-------------Create Vector Store--------------------------
#Chroma DB
from langchain.vectorstores import Chroma
#vectordb = Chroma.from_documents(documents=texts, embedding=embeddings,persist_directory="chroma_db")
# load from disk
#vectordb = Chroma(persist_directory="./chroma_db", embedding_function=embeddings)
#vectordb.get()
# Use FAISS vector DB
from langchain.vectorstores.faiss import FAISS
index = FAISS.from_documents(texts, embeddings)
index.save_local("faiss_index")
#index = FAISS.load_local("faiss_index", embeddings,allow_dangerous_deserialization=True)The last step is to create a retriever to extract information from the vector store.
############### Retrival ########################
##################################################
#Initialize the retrievaer
# retriever = vectordb.as_retriever(search_kwargs={"k": 3})
retriever = index.as_retriever()
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
verbose=True)Done! Time to ask the model
results = qa.invoke("summarize the document in 10 bullets")
results['result'] #output are saved in dictionary format
#approach 2
def test_rag(qa, query):
print(f"Query: {query}\n")
result = qa.run(query)
print("\nResult: ", result)
query = "What were the main topics in the State of the Union in 2023? Summarize. Keep it under 200 words."
test_rag(qa, query)
#document search
docs = index.similarity_search(query)
print(f"Query: {query}")
print(f"Retrieved documents: {len(docs)}")
for doc in docs:
doc_details = doc.to_json()['kwargs']
print("Source: ", doc_details['metadata']['source'])
print("Text: ", doc_details['page_content'], "\n")##############################################################
######## ParentDocumentRetriever: ParentDocumentRetriever ####
##############################################################
#Retrieving larger chunks
#Sometimes, the full documents can be too big to want to retrieve them as is. In that case,
#what we really want to do is to first split the raw documents into larger chunks, and
#then split it into smaller chunks. We then index the smaller chunks, but on retrieval we retrieve
#the larger chunks (but still not the full documents).
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
# This text splitter is used to create the parent documents - The big chunks
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)
# This text splitter is used to create the child documents - The small chunks
# It should create documents smaller than the parent
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name="split_parents", embedding_function=embeddings)
# The storage layer for the parent documents
store = InMemoryStore()
big_chunks_retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
)
big_chunks_retriever.add_documents(docs)
len(list(store.yield_keys()))
retrieved_docs = big_chunks_retriever.get_relevant_documents("what is yourTopic")
####### Retrival:big_chunks_retriever #############
##################################################
#Initialize the retrievaer
# retriever = vectordb.as_retriever(search_kwargs={"k": 3})
#retriever = index.as_retriever()
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=big_chunks_retriever,
verbose=True)
results = qa.invoke("summarize the document in 10 bullets")
results['result']Congratulations, now we can create and design our own LLM including Retrieval-Augmented Generation(RAG) models
Next, we will learn ways to improve the accuracy of our model using Prompt Engineering like Zero-Shot Learning, One-Shot Learning,Few Shots, ReAct, Chain-of-Though, Iterative Prompting, Negative Prompting, Hybrid Prompting, and Prompt Chaining etc.
Until then feel free to reach out. Thanks for your time, if you enjoyed this short article there are tons of topics in advanced analytics, data science, and machine learning available in my medium repo. https://medium.com/@bobrupakroy
Some of my alternative internet presences are Facebook, Instagram, Udemy, Blogger, Issuu, Slideshare, Scribd, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Let me know if you need anything. Talk Soon.



Comments
Post a Comment