LSTM-AutoEncoders. Understand and perform Composite & Standalone LSTM Encoders to recreate sequential data.

What are AutoEncoders?
AutoEncoder is an artificial neural network model that seeks to learn from a compressed representation of the input.
There are various types of autoencoders available suited for different types of scenarios, however, the commonly used autoencoder is for feature extraction.
Combining feature extraction models with different types of models has a wide variety of applications.
Feature Extraction Autoencoders models for prediction sequence problems are quite challenging not because the length of the input can vary, its because machine learning algorithms and neural networks are designed to work with fixed length inputs.
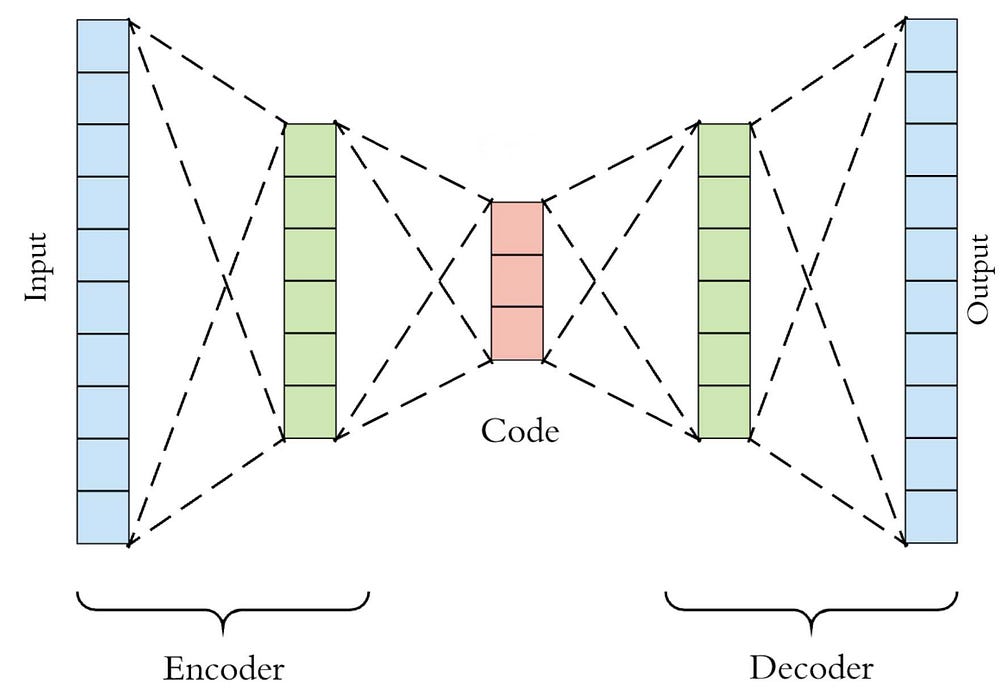
Another problem with sequence prediction is the temporal ordering of the observations can make it challenging to extract features. Therefore special predictive models were developed to overcome such challenges. These are called Sequence-to-sequence, or seq2seq. and the widely used we already have heard of are the LSTM models.
LSTM
Recurrent neural networks such as the LSTM or Long Short-Term Memory network are specially designed to support the sequential data.
They are capable of learning the complex dynamics within the temporal ordering of input sequences as well as using an internal memory to remember or use information across long input sequences.
NOW combing Autoencoders with LSTM will allow us to understand the pattern of sequential data with LSTM then extract the features with Autoencoders to recreate the input sequence.
In other words, for a given dataset of sequences, an encoder-decoder LSTM is configured to read the input sequence, encode it and recreate it. The performance of the model is evaluated based on the model’s ability to recreate the input sequence.
Once the model achieves a desired level of performance in recreating the sequence. The decoder part of the model can be removed, leaving just the encoder model. Now further this model can be used to encode input sequences.
Let’s understand this with the help of an example
Simple LSTM Autoencoder
To reconstruct each input sequence.
First, we will import all the required libraries.
from numpy import array
from keras.models import Sequential
from keras.layers import LSTM
from keras.layers import Dense
from keras.layers import RepeatVector
from keras.layers import TimeDistributed
Then we will create a sample of simple sequential data for input and reshaping it into the preferred LSTM input data format/shape of [samples,timesteps,features]
#define input sequence
sequence = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9])
#reshape input into [samples, timesteps, features]
n_in = len(sequence) #i.e. 9
sequence = sequence.reshape((1, n_in, 1))
Next, we will define the encoder-decoder LSTM architecture that expects input sequences with 9-time steps and on feature and outputs a sequence with 9-time steps and 1 feature.
model = Sequential()
model.add(LSTM(100, activation='relu', input_shape=(n_in,1)))
model.add(RepeatVector(n_in))
#RepeatVectorlayer repeats the incoming inputs a specific number of time
‘’’ For encoder-decoder, input is squashed into a single feature vector, if we want our output to regenerate the same dimension as the original input, we need to convert this single feature vector 1D to 2D by replicating it using RepeatVector().’’’
model.add(LSTM(100, activation='relu', return_sequences=True))
model.add(TimeDistributed(Dense(1))) #This wrapper allows to apply a layer to every temporal slice of an input.
model.compile(optimizer='adam', loss='mse')
#fit model
model.fit(sequence, sequence, epochs=300, verbose=0)
#Reconstruct the input sequence
p = model.predict(sequence, verbose=0)
print(p[0,:,0])
done that’s it….
Now the above will give the reconstructed input sequence.
[0.1100185 0.20737442 0.3037837 0.40000474 0.4967959 0.59493166
0.69522375 0.7985466 0.9058684 ]
Let me put all of the codes together.
from numpy import array
from keras.models import Sequential
from keras.layers import LSTM
from keras.layers import Dense
from keras.layers import RepeatVector
from keras.layers import TimeDistributed
#define input sequence
sequence = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9])
#reshape input into [samples, timesteps, features]
n_in = len(sequence) #i.e. 9
sequence = sequence.reshape((1, n_in, 1))
model = Sequential()
model.add(LSTM(100, activation='relu', input_shape=(n_in,1)))
model.add(RepeatVector(n_in))
#RepeatVectorlayer repeats the incoming inputs a specific number of time
model.add(LSTM(100, activation='relu', return_sequences=True))
model.add(TimeDistributed(Dense(1))) '''#This wrapper allows to apply a layer to every temporal slice of an input.'''
model.compile(optimizer='adam', loss='mse')
#fit model
model.fit(sequence, sequence, epochs=300, verbose=1)
#Reconstruct the input sequence
p = model.predict(sequence, verbose=0)
print(p[0,:,0])
Now let's try something a bit complex having one encoder and 2 decoders. We will name it Composite LSTM AutoEncoders where 1 decoder will be used for reconstruction and another decoder will be used for prediction.
First, the encoder is defined
#define the encoder
visible = Input(shape=(n_in,1))
encoder = LSTM(100, activation='relu')(visible)
#Decoder 1 for reconstruction
decoder1 = RepeatVector(n_in)(encoder)
decoder1 = LSTM(100, activation='relu', return_sequences=True)(decoder1)
decoder1 = TimeDistributed(Dense(1))(decoder1)
#Decoder 2 for prediction
decoder2 = RepeatVector(n_out)(encoder)
decoder2 = LSTM(100, activation='relu', return_sequences=True)(decoder2)
decoder2 = TimeDistributed(Dense(1))(decoder2)
then we will tie up the encoder and the decoders.
model = Model(inputs=visible, outputs=[decoder1, decoder2])
The workflow of the composite encoder will be something like this.

#LSTM-AutoEncoder
from keras.layers import Dense
from keras.layers import RepeatVector
from keras.layers import TimeDistributed
from keras.utils import plot_model
from numpy import array
from keras.layers import Input
from keras.models import Model
#define input sequence
seq_in = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9])
#reshape input into [samples, timesteps, features]
n_in = len(seq_in)
seq_in = seq_in.reshape((1, n_in, 1))
#prepare output sequence
seq_out = seq_in[:, 1:, :]
n_out = n_in - 1
#define encoder
visible = Input(shape=(n_in,1))
encoder = LSTM(100, activation='relu')(visible)
#Decoder 1 for prediction
decoder1 = RepeatVector(n_in)(encoder)
decoder1 = LSTM(100, activation='relu', return_sequences=True)(decoder1)
decoder1 = TimeDistributed(Dense(1))(decoder1)
#Decoder 2 for prediction
decoder2 = RepeatVector(n_out)(encoder)
decoder2 = LSTM(100, activation='relu', return_sequences=True)(decoder2)
decoder2 = TimeDistributed(Dense(1))(decoder2)
#tie up the encoder and the decoders
model = Model(inputs=visible, outputs=[decoder1, decoder2])
model.compile(optimizer='adam', loss='mse')
#fit model
model.fit(seq_in, [seq_in,seq_out], epochs=300, verbose=0)
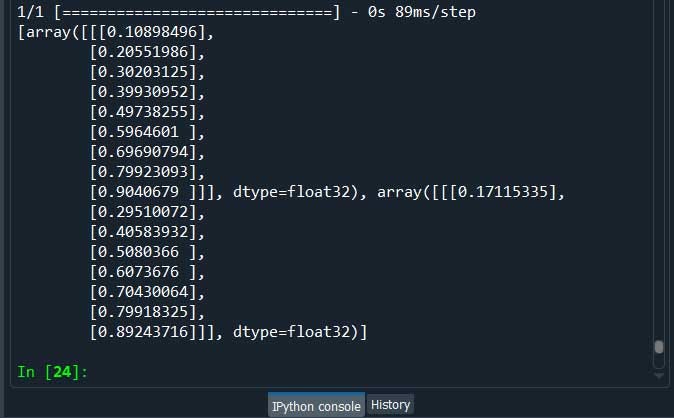
#demonstrate prediction
results = model.predict(seq_in, verbose=1)
print(results)
Now once the autoencoder has been lifted the decoder is no longer needed and can be removed and we can keep the encoder as a standalone model.
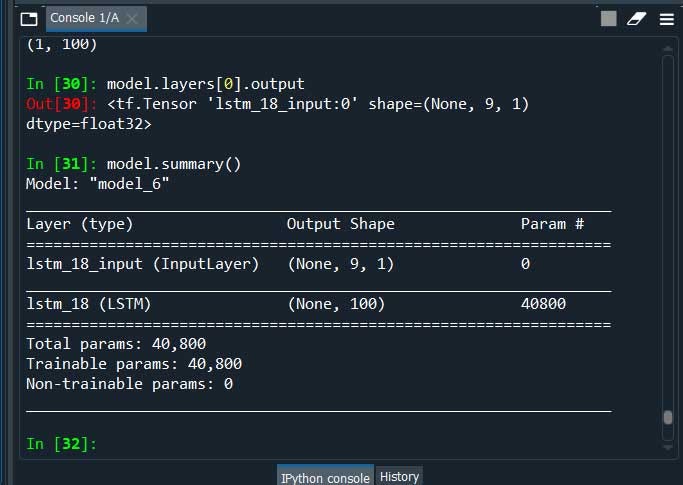
The encoder can be then used to transform input sequences to a fixed length encoded vector. We can perform this by creating a new model that has the same inputs as the original model. And outputs directly from the end of the encoder model, before the RepeatVector Layer.
#the encoder LSTM as the output layer
model = Model(inputs=model.inputs, outputs=model.layers[0].output)
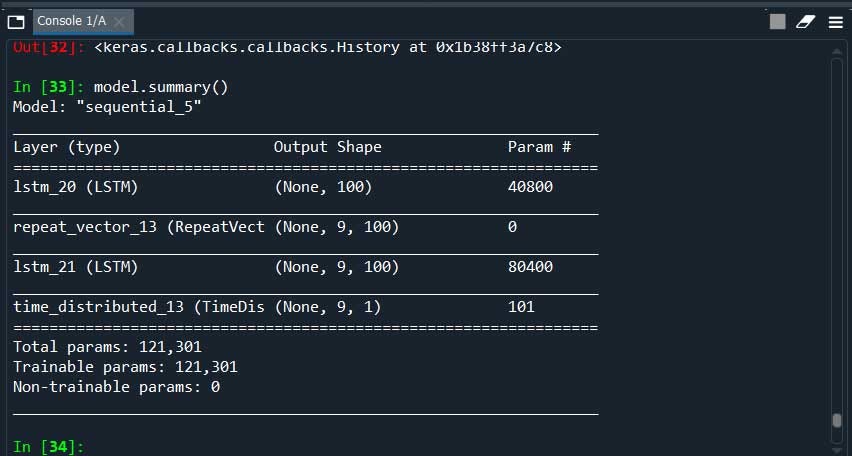
We can view each layer using model summary()
Here’s what we have in our case
from numpy import array
from keras.models import Sequential
from keras.models import Model
from keras.layers import LSTM
from keras.layers import Dense
from keras.layers import RepeatVector
from keras.layers import TimeDistributed
from keras.utils import plot_model
#define input sequence
sequence = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9])
#reshape input into [samples, timesteps, features]
n_in = len(sequence)
sequence = sequence.reshape((1, n_in, 1))
#define model
model = Sequential()
model.add(LSTM(100, activation='relu', input_shape=(n_in,1)))
model.add(RepeatVector(n_in))
model.add(LSTM(100, activation='relu', return_sequences=True))
model.add(TimeDistributed(Dense(1)))
model.compile(optimizer='adam', loss='mse')
#fit model
model.fit(sequence, sequence, epochs=300, verbose=1)
#the encoder LSTM as the output layer
#We can view each layer using model.summary()
model.summary()
model = Model(inputs=model.inputs, outputs=model.layers[0].output)
#get the feature vector for the input sequence
results = model.predict(sequence)
print(results)
print(results.shape)
model.summary()
Now, this standalone encoder model can be used later. However, if we need more than 9 sequences then we have to increase our sequence length/time steps else it will overkill the 9 sequence prediction model.
Thanks for your time I tried my best to keep it short and simple keeping in mind to use this code in our daily life. This article is based on ‘machinelearningmastry’ blog where I tried to recreate a simpler and easier version of ‘How to harness the high accuracy predictions with LSTM-AutoEncoders’
I hope you enjoyed it.
Feel Free to ask because “Curiosity Leads To Perfection”
Some of my alternative internet presences are Facebook, Instagram, Udemy, Blogger, Issuu, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Stay tuned for more updates.! have a good day….
~ Be Happy and Enjoy!



Comments
Post a Comment