SFT vs DFO vs PEFT vs GRPO: Choosing the Right Fine-Tuning Strategy for LLMs
SFT vs DFO vs PEFT vs GRPO: Choosing the Right Fine-Tuning Strategy for LLMs
Large Language Models (LLMs) like GPT, LLaMA, and Mistral have changed the way we interact with data and automation. But to make these models work effectively for specialized domains — like construction, BIM, finance, or healthcare — we often need to adapt them. That’s where fine-tuning techniques come into play.

Four commonly discussed approaches are:
- SFT (Supervised Fine-Tuning)
- DFO (Direct Preference Optimization)
- PEFT (Parameter-Efficient Fine-Tuning)
- GRPO (Group Relative Policy Optimization)
Each has its own strengths, costs, and ideal use cases. Let’s break them down and compare them.
1️⃣ Supervised Fine-Tuning (SFT)
SFT is the traditional fine-tuning approach, where the entire LLM’s weights are updated using a labeled dataset of input-output pairs.
How It Works
- Take a pretrained base model.
- Train it on a task-specific dataset (e.g., “BIM sheet correction → corrected sheet name”).
- Update all parameters in the network.
✅ Pros
- Best for specialized expertise transfer.
- Model fully adapts to the domain.
- Works well with large datasets.
❌Cons
- Expensive (GPU-heavy).
- Requires tens of thousands of samples.
- Risk of catastrophic forgetting (losing base model skills).
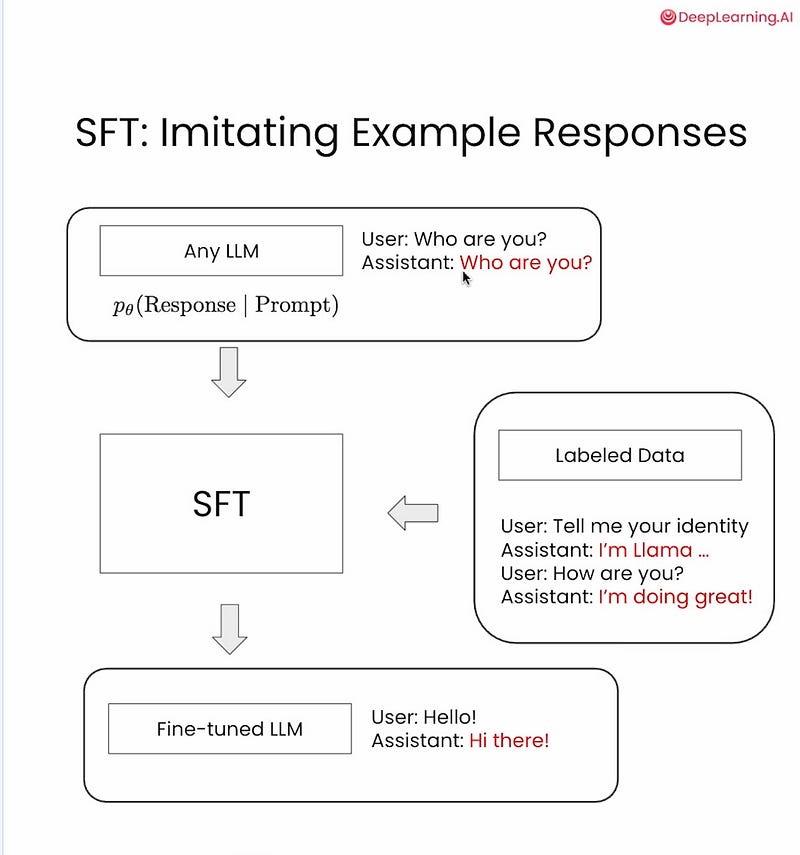
Below are some of the implementation examples from deeplearning.ai for implementing the SFT. For hands-on, you can enroll on their site.


2️⃣ Direct Preference Optimization (DFO)
DFO is a reinforcement learning-free method for aligning LLMs with human preferences, directly optimizing model output quality without needing a separate reward model (like RLHF does).
In other words, Direct Preference Optimization (DPO) is a contrastive learning method that leverages both positive and negative samples. It minimizes a contrastive loss that penalizes negative responses while encouraging positive ones.
The DPO loss is essentially a cross-entropy loss applied to the difference in rewards between positive and negative responses, where the rewards are estimated using a reparameterized reward model
How It Works
- You collect pairs of responses: one preferred, one less preferred.
- Instead of training a reward model, DFO optimizes the model parameters directly to increase preference likelihood.
✅ Pros
- Simpler than RLHF, no extra reward model.
- Good for alignment with subjective preferences (e.g., polite tone, safety).
- More stable training.
❌ Cons
- Needs labeled preference datasets.
- Does not improve factual knowledge or domain adaptation as much as SFT.

Below are some of the implementation examples from deeplearning.ai for implementing the DFO. For hands-on, you can enroll on their site.


3️⃣ Parameter-Efficient Fine-Tuning (PEFT)
PEFT allows fine-tuning by adding small trainable adapters (LoRA, Prefix-tuning, P-Tuning v2) while keeping most of the base model frozen.
How It Works
- Base LLM remains fixed.
- Lightweight parameters are injected and trained (often <1% of the model’s weights).
- Multiple adapters can be swapped for different domains. Check the type of adapter in my previous article.
Explore LLM adapters to improve the efficiency of the LLMSbobrupakroy.medium.com

For more in-depth Transformer architecture, follow my previous article:
Transformers Unpacked: An In-Depth Guide to Encoder-Decoder Architecture, Positional Encoding, Multi-Head Attention…bobrupakroy.medium.com
It tries to modify the weights of the adapter layer to calibrate the output based on the dataset that we provide to fine-tune
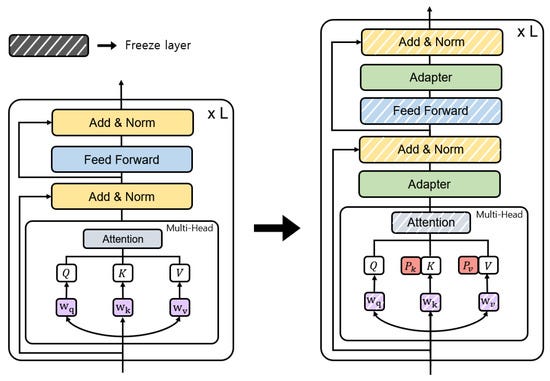
PEFT methods (like LoRA, Adapter, Prefix Tuning) aim to fine-tune a small subset of model parameters or add new trainable parameters while freezing the original model weights.
So in PEFT methods like LoRA we can modify the components such as

We can view the layers by simply using
from torchsummary import summary
summary(model, input_size=(seq_len, hidden_dim))
#or
from transformers import GPT2Model
# Load GPT-2
model = GPT2Model.from_pretrained("gpt2")
# Print the full model architecture
print(model)
GPT2Model(
(wte): Embedding(50257, 768)
(wpe): Embedding(1024, 768)
(drop): Dropout(p=0.1, inplace=False)
(h): ModuleList(
(0): Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): Attention(
(c_attn): Conv1D(2304, 768)
(c_proj): Conv1D(768, 768)
...
)
...
)
...
)
(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
#Key parts:
#c_attn: Projects to Q, K, V (768 × 3 = 2304)
#c_proj: Final attention projection (P layer, in your terms)
#These are under each Block inside h (the transformer layers)✅ Pros
- 10–100x cheaper than SFT.
- Works with small datasets (few thousand samples).
- You can keep one base model with many domain adapters.
- Easy deployment and maintenance.
❌ Cons
- Slightly lower accuracy than full SFT for highly complex tasks.
- Still inherits the limitations of base model.
Here is the link below to have a more detailed walkthrough of PEFT using LoRA
Master the Art of Efficient Model Adaptation: Explore PEFT and LoRA Techniques for Fine-Tuning LLMs and Dive into Route…bobrupakroy.medium.com
4️⃣ Proximal Policy Optimization (PPO)
A reinforcement learning algorithm used in RLHF (Reinforcement Learning with Human Feedback). PPO trains a policy model using a reward model, optimizing the model to generate better responses.
How It Works
- Start with a base model (e.g., GPT).
- Generate candidate outputs for a prompt.
- A reward model (trained on human feedback) scores these outputs.
- PPO optimizes the LLM to maximize expected reward while staying close to the original model (to avoid “drifting”).
✅ Pros
- The classic RLHF method (used in early ChatGPT training).
- Improves helpfulness, safety, and preference alignment.
- Works well with continuous feedback loops.
❌ Cons
- Complex, costly, multi-step pipeline:
- Needs SFT base → Reward model → PPO optimization.
- Sensitive to reward model quality.
- Not meant for domain knowledge training.

Here in the flow diagram, we have 2 models: the Reward model(base model) and the reference model, which gets compared by using KL divergence and then updates the Peft updated model
A detailed walkthrough of PPO implementation:
Proximal Policy Optimization (PPO) offers a unique method where reinforcement learning agents make decisions within an…bobrupakroy.medium.com
5️⃣ Group Relative Policy Optimization (GRPO)
GRPO is a reinforcement learning approach that improves LLM alignment by comparing groups of model responses and optimizing toward the relative ranking of good vs bad outputs.
Think of it as “RLHF but without a separate reward model,” using relative preferences across multiple answers instead of a single score.
How It Works
- Model generates multiple outputs for a prompt.
- A scoring function or human raters rank the outputs.
- GRPO adjusts the model toward better-ranked outputs.
✅ Pros
- Efficient compared to PPO (used in RLHF).
- Works well for safety, reasoning, and multi-turn coherence.
- Useful when you can generate relative preference data instead of absolute rewards.
❌ Cons
- More complex than SFT or PEFT.
- Needs large-scale inference to produce candidate responses.
- Not primarily for knowledge adaptation (focus is alignment, not domain learning).

Here in the following diagram, we dont have another LLM model to compare the output as in PPO instead, we use Reward Server i.e. any business logic via python script to rank the output.
🆚 Comparison Table


💡 Final Thought
In 2025, PEFT + RAG remains the most practical solution for enterprises to adapt LLMs for their domain (like BIM or construction).
For human-aligned, safe behavior, reinforcement learning techniques like DFO, GRPO, or PPO are layered on top.
Thanks for your time, if you enjoyed this short article there are tons of topics in advanced analytics, data science, and machine learning available in my medium repo. https://medium.com/@bobrupakroy
Some of my alternative internet presences are Facebook, Instagram, Udemy, Blogger, Issuu, Slideshare, Scribd, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Let me know if you need anything. Talk Soon.
Check out the links, i hope it helps.


Comments
Post a Comment