Understanding Transformer Architecture: Revolutionizing Natural Language Processing Through Self-Attention Encoder/Decoder and Deep Learning.
Transformers Unpacked: An In-Depth Guide to Encoder-Decoder Architecture, Positional Encoding, Multi-Head Attention, and Feed-Forward Layers
Hi everyone, i hope you are doing good. Lets unpack the transformer.
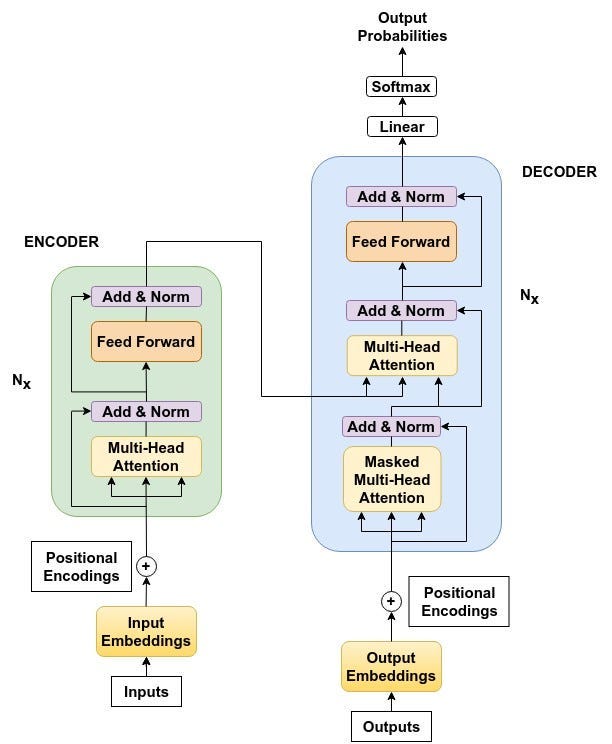
The Transformer architecture is one of the most influential advancements in deep learning, powering models like BERT, GPT, and many others that have revolutionized natural language processing (NLP) and beyond. It relies on self-attention, layered processing, and a unique approach to handling sequential data. This guide breaks down each key component of transformers, including the encoder-decoder structure, positional encoding, multi-head attention, and feed-forward layers.
Encoder ~
Of course, we will start with Inputs. let’s say “Please like and subscribe”
Definitely we cant push characters or strings to the algorithm they only with numbers, we will convert them into embeddings. Vector Embeddings
Vector Embeddings:
Vector embeddings are a way of representing complex objects (like words, sentences, )as dense, fixed-length vectors of numbers. These vectors capture the relationships, meanings, or features of the objects in a way that similar objects are mapped to similar vector representations.
For example, in natural language processing, word embeddings (like Word2Vec or GloVe) represent words as vectors, and words with similar meanings are closer together in the vector space. The idea is that these vectors make it easier for machines to analyze and compare objects by using mathematical operations like distance or cosine similarity
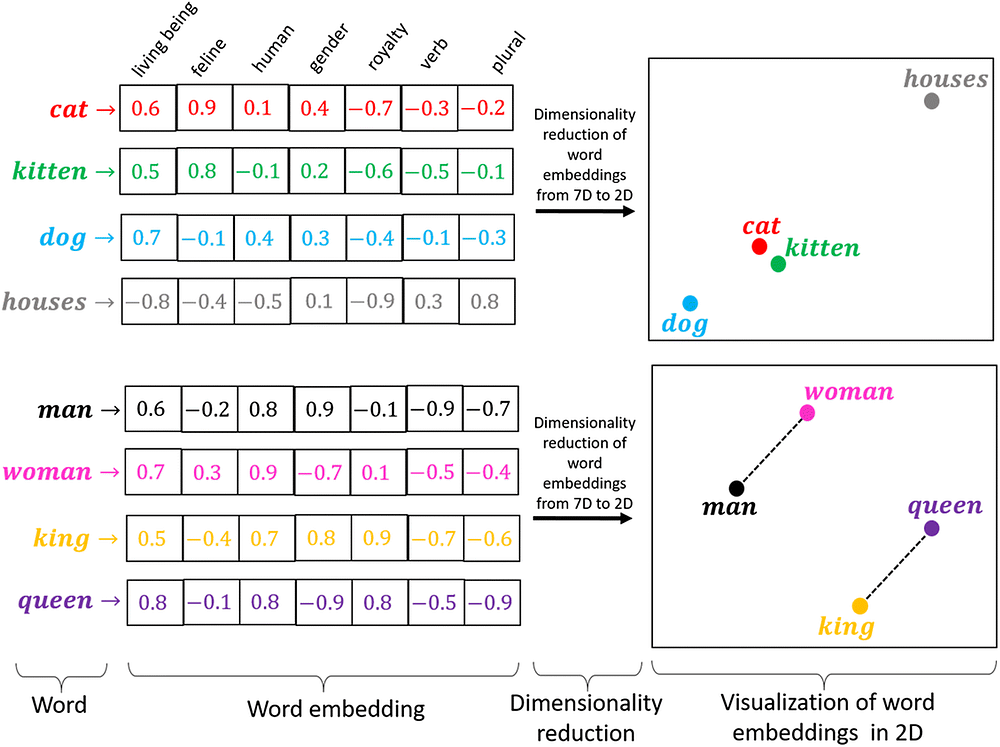
However, vector embeddings lose its sequential learning as it only concentrates in getting the similar/correlated words. Unlike RNN, LSTM they were designed to learn sequential patterns. lets say “ i like to eat vegies” and not “ vegies eat like i”
Now this issue is solved by the positional encodings.
Positional Encodings:
Instead of adding more numbers to vector embeddings. Positional encodings is calculated by using sin and cos theta, Positional encoding describes the location or position of an entity in a sequence so that each position is assigned a unique representation
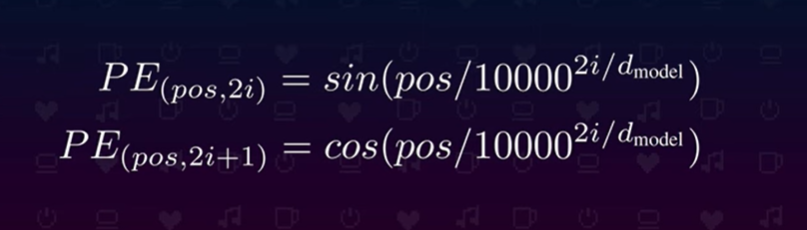
so every increase in input(tokens/embeddings/word) we will have a different frequency of sin or cos theta value.
you can refer to the above word embeddings table and visualize sin & cos theta wave for each words
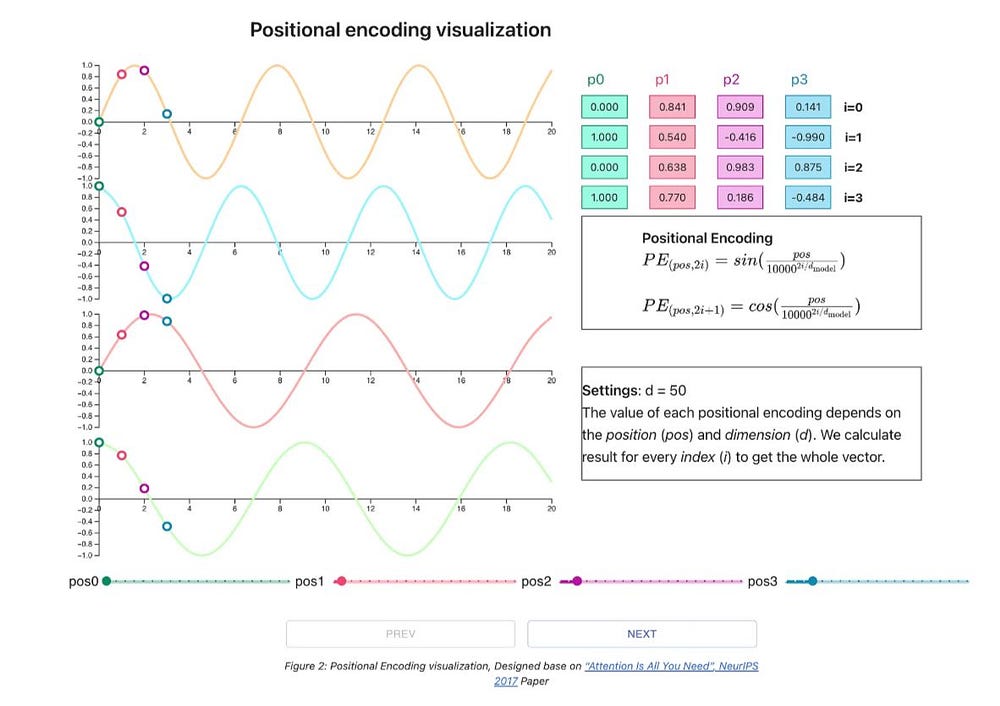
Now of course this is again translated into numbers and add it to the vector embeddings.
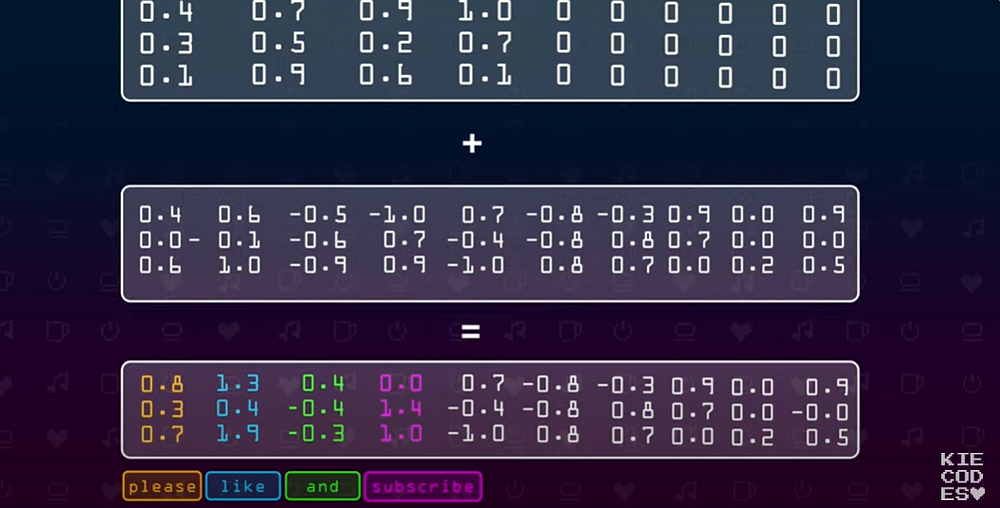
Next the values are pushed to MultiHead Attention Layer
Coding the Positional Encoding Matrix from Scratch
#The code is simplified to make the understanding of positional encoding easier.
import numpy as np
import matplotlib.pyplot as plt
def getPositionEncoding(seq_len, d, n=10000):
P = np.zeros((seq_len, d))
for k in range(seq_len):
for i in np.arange(int(d/2)):
denominator = np.power(n, 2*i/d)
P[k, 2*i] = np.sin(k/denominator)
P[k, 2*i+1] = np.cos(k/denominator)
return P
P = getPositionEncoding(seq_len=4, d=4, n=100)
print(P)[[ 0. 1. 0. 1. ]
[ 0.84147098 0.54030231 0.09983342 0.99500417]
[ 0.90929743 -0.41614684 0.19866933 0.98006658]
[ 0.14112001 -0.9899925 0.29552021 0.95533649]]Understanding the Positional Encoding Matrix
#To understand the positional encoding, let’s start by looking at the sine wave for different positions with n=10,000 and d=512.
def plotSinusoid(k, d=512, n=10000):
x = np.arange(0, 100, 1)
denominator = np.power(n, 2*x/d)
y = np.sin(k/denominator)
plt.plot(x, y)
plt.title('k = ' + str(k))
fig = plt.figure(figsize=(15, 4))
for i in range(4):
plt.subplot(141 + i)
plotSinusoid(i*4)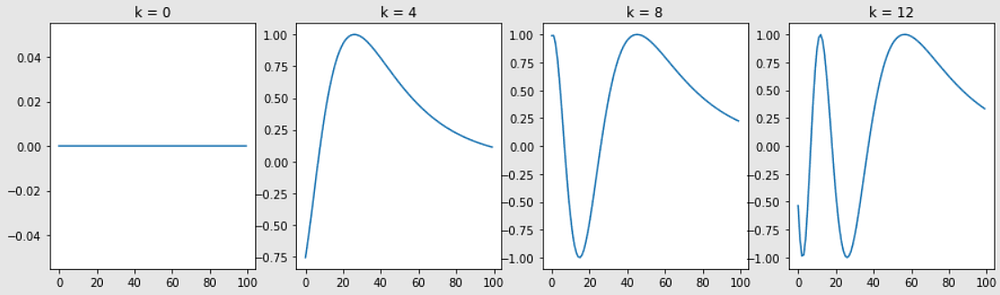
Final Output of the Positional Encoding Layer?
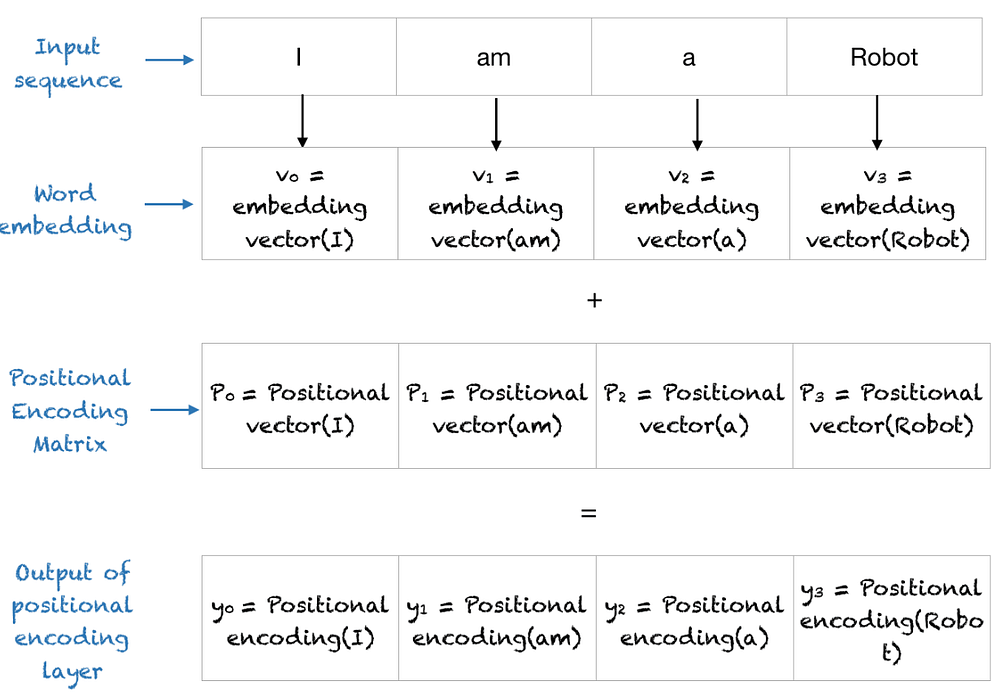
Multi-Head Attentions layer
Frist understand what is self- attention?
Self attention allows them to understand the relationships between different words in a sentence, regardless of how far apart the words are. This mechanism enables transformers to “pay attention” to different parts of a sentence dynamically, based on context, which helps capture the meaning more accurately.
In simple words it find how similar each words to all of the words in the sentence including self.
Key Steps in Self-Attention
In self-attention, each word in a sentence is compared to every other word (including itself) to determine its relevance to them. Here’s how it works:
- Input Embedding and Position Encoding:
- Each word in a sentence is converted into an embedding, which is a fixed-size vector that represents the word in a way that captures its meaning. Position encoding is added to each word embedding to preserve the order of words in the sequence.
2. Creating Queries, Keys, and Values:
- For each word, the model creates three vectors: a Query (Q), a Key (K), and a Value (V). These vectors are derived by multiplying the word embedding by weight matrices (which are learned during training).
- The Query vector represents “what this word is looking for,” the Key vector represents “what this word contains,” and the Value vector represents “the information this word holds.”
3. Calculating Attention Scores:
- For each word, we calculate the attention score with every other word in the sequence by taking the dot product of the Query vector of one word with the Key vector of another word. This tells us how relevant one word is to another in the context of the sentence.
- These scores are then scaled (divided by the square root of the vector size) and normalized using the softmax function to get a probability distribution. The softmax ensures that the scores add up to 1 and are easier to interpret as relative importance.
4. Weighting the Values:
- The scores obtained from softmax are used as weights to adjust the Value vectors. Words with higher relevance scores contribute more to the output for that position.
- For each word, the model sums the weighted Value vectors of all words, resulting in a new representation of that word that takes into account the context provided by all other words in the sentence.
5. Multi-Head Attention:
- In practice, transformers use multiple attention “heads,” each with its own set of Query, Key, and Value matrices. This allows the model to capture different types of relationships and dependencies simultaneously.
- The outputs of these heads are then concatenated and transformed to produce the final output for that layer.
Why Self-Attention is Powerful
- Captures Long-Range Dependencies: Self-attention allows each word to “attend” to all other words, even if they are far apart in the sentence. This is important for understanding long-range dependencies, like in sentences with complex structures.
- Context-Dependent Representations: The representation of each word changes dynamically based on its relationship with other words. For example, in “bank” (financial) vs. “bank” (river), self-attention can use the surrounding context to differentiate between meanings.
- Parallelizable: Unlike RNNs, which process words sequentially, self-attention allows for parallel processing. This significantly speeds up training and inference times, especially on large datasets.
Example
Consider the sentence: “The cat sat on the mat.”
For the word “cat,” self-attention will compute how relevant each other word is to “cat.” If “sat” and “mat” are deemed more relevant to “cat” than “the” or “on,” they will have higher attention scores, making their Value vectors more influential in the final representation of “cat” in this context.
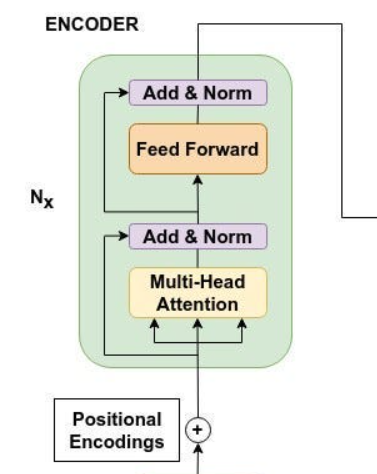
Normalization / Add * Norm
We are already seen why we need normalization in machine learning tutorials.
- Stabilizes the gradients: Without scaling, large values in the dot products can result in extremely small gradients after applying softmax, making training slower and less stable.
- Improves numerical stability: Scaling prevents values from growing too large, reducing the risk of exploding gradients or saturation of the softmax function.
Forward Feed Layer:
The Feed-Forward layer is a fully connected neural network layer applied independently to each position (word or token) in the input sequence. It follows the self-attention layer in each transformer block.
The Feed-Forward layer consists of two linear transformations with a ReLU (or similar) activation in between. The operations are performed independently on each token, meaning each token’s representation is transformed without regard to the other tokens. This is often called a “position-wise” feed-forward layer because it applies the same transformation to each position in the sequence.
The Feed-Forward layer serves several purposes in the transformer architecture:
- Non-Linearity: The ReLU activation introduces non-linear transformations, which allows the model to capture complex patterns in the data. Without this non-linearity, the model would be limited to linear transformations, which might not be sufficient for capturing intricate dependencies in language.
- Feature Transformation: By projecting to a higher dimension and then back down, the Feed-Forward layer enables richer transformations of the input features. This can help the model learn better representations for each token.
- Token-Wise Processing: Since the Feed-Forward layer is applied to each token independently, it doesn’t mix information between different tokens in the sequence. This is complementary to the self-attention layer, which mixes information across tokens. Together, they provide both global (contextual) and local (token-specific) processing.
Residual Connections
means we are adding input of one layer to the output of one layer.
- Helps Gradient Flow: Residual connections make it easier for gradients to flow back through the network, which reduces the risk of vanishing gradients in deep networks. This helps each layer learn more effectively during training.
- Reduces Information Loss: By adding the original input to the output of each sub-layer, residual connections ensure that each layer has access to information from previous layers. This helps preserve important information, even as it passes through many layers.
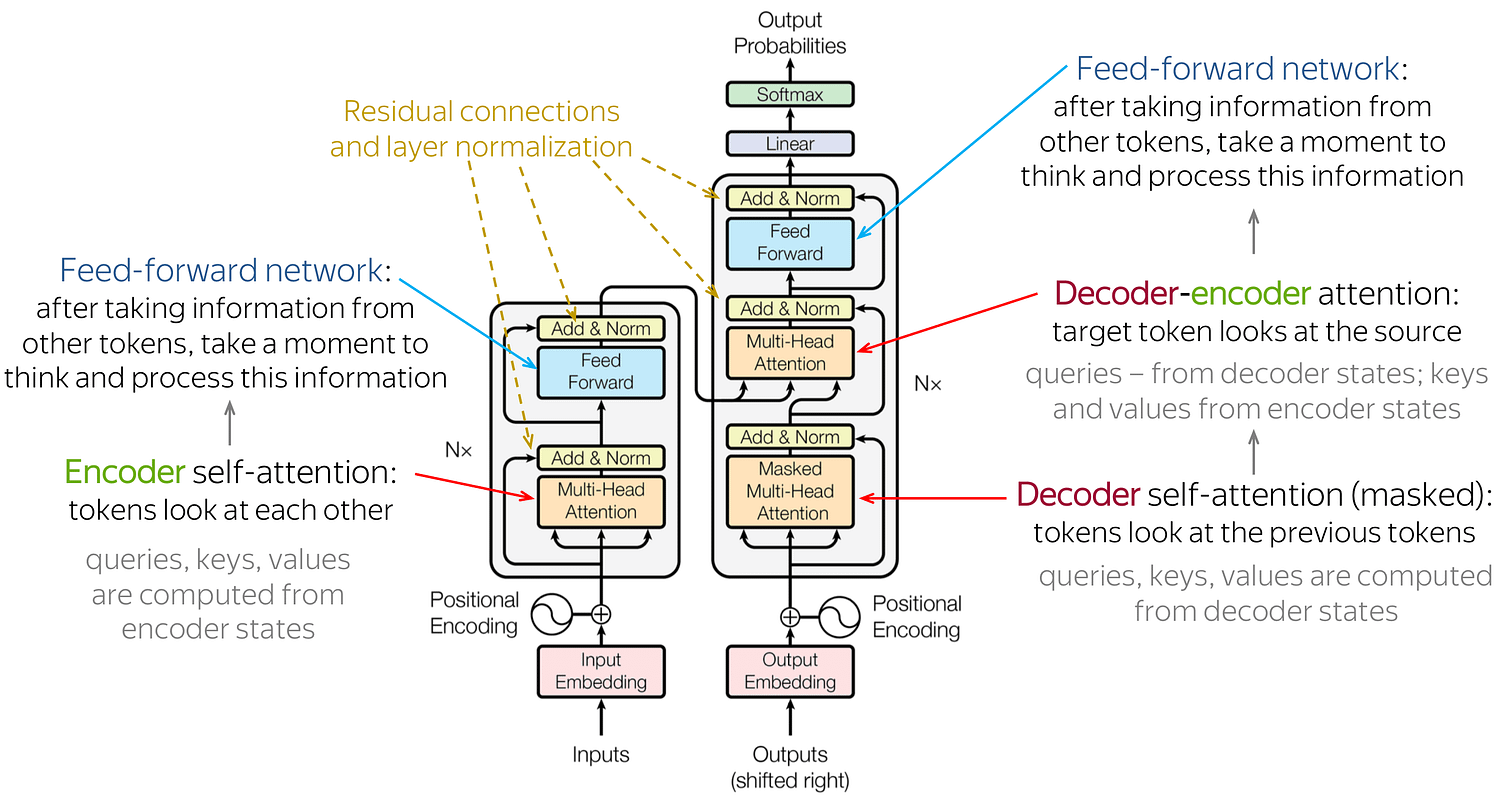
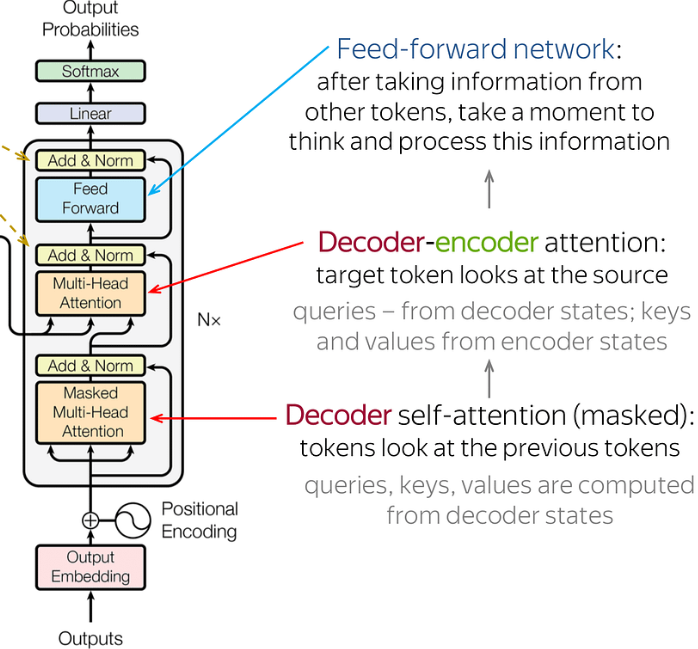
Next: The Decoder Transformer
predicts the next token from previous tokens only. while encoder looks into previous and past both tokens. As the decoder looks only for previous tokens this is called as masked attention head.
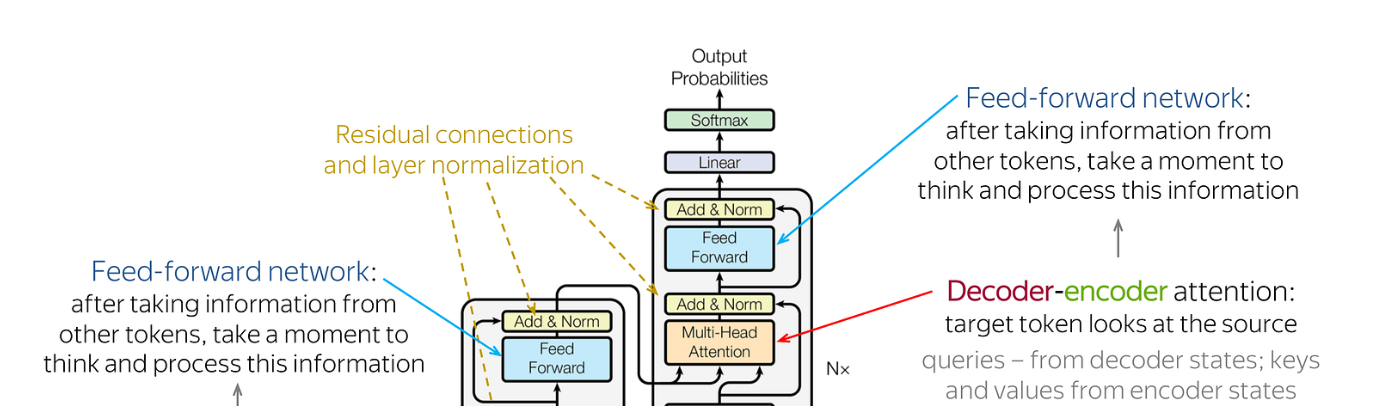
So the output from the encoder is forwarded to the decoder where the Decoder-Encoder attention looks at the source, queries, keys & values from the encoder states. Then it continues to Linear function & softmax function to get the multi-class probabilities scores. Softmax if you remmber form deep learning is used for multi-class prediction. Example. vacation: 0.7 work: 0.6 somewhere 0.3 here the word ‘vacation will be forward to the next loop to predict the sequence ( lets say the prediction is “ i want to for a vacation to the mountains”)
Now the previous output ‘vacation’ is forward to the ‘Mask Multi-head Attention’ to predict the next word, also in the decoder-encoder attention it will look for relevance with the source. Mask Attention layer only looks for previous tokens/words to predict the next word. At some point of the loop where the probability scores are very low it will stop the iteration.
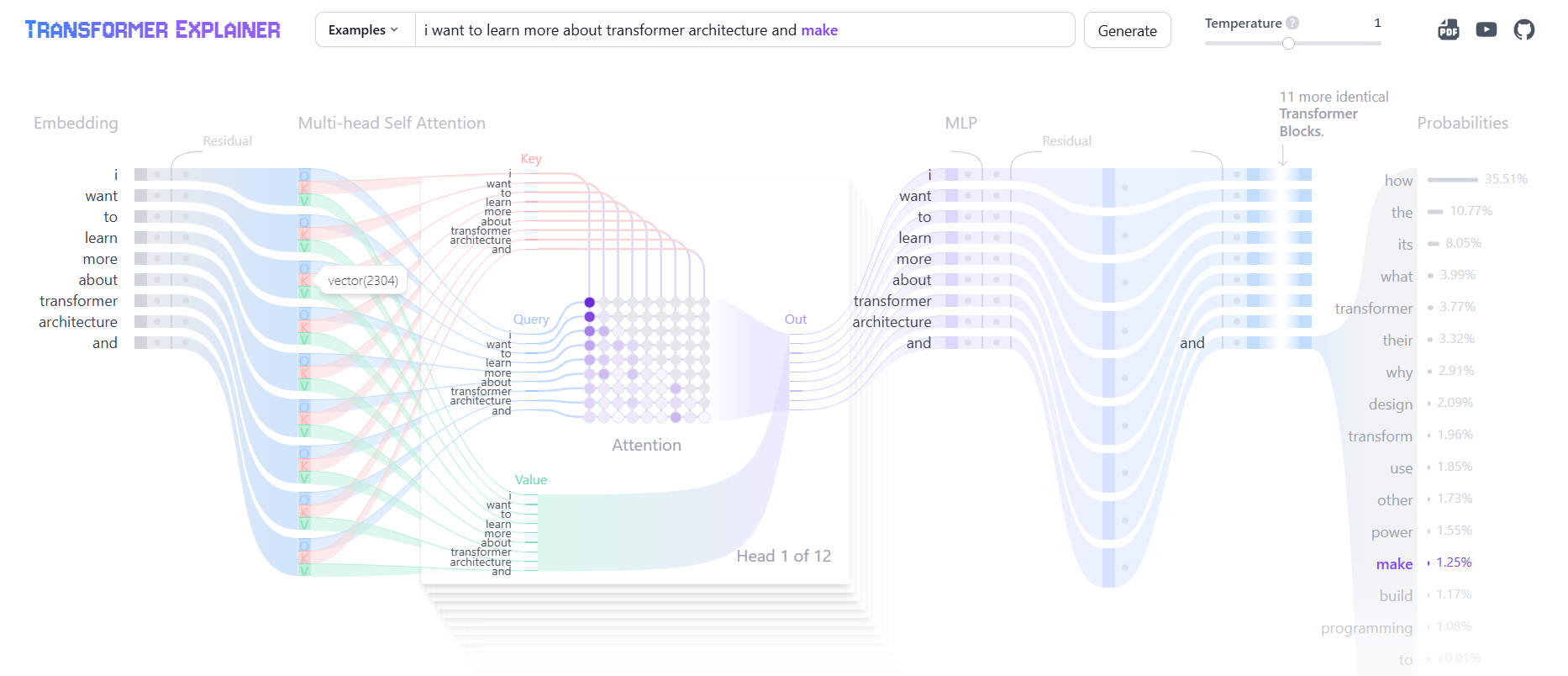
Have a look at the interactive visualization on the transformer works.
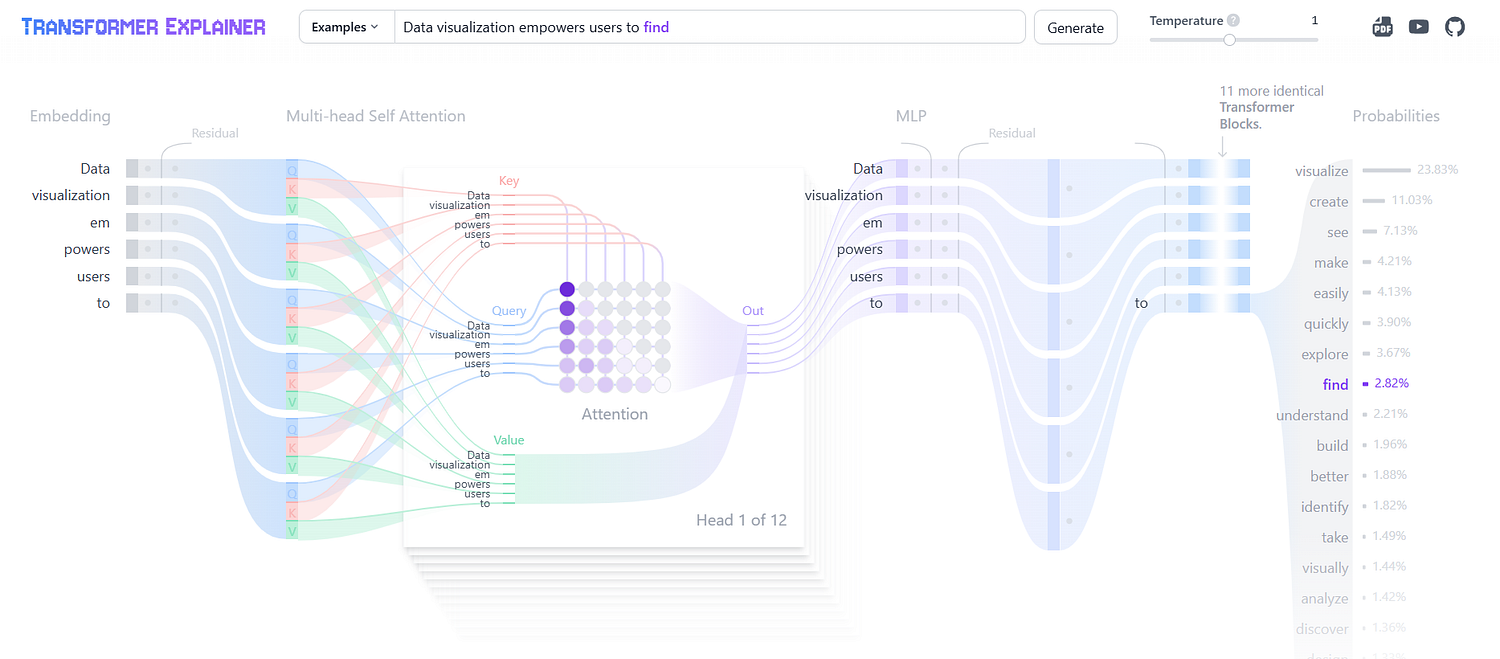
An interactive visualization tool showing you how transformer models work in large language models (LLM) like GPT.poloclub.github.io
Enjoyed the article? let me know your thoughts…
There are tons of topics in advanced analytics, data science, and machine learning available in my medium repo. https://medium.com/@bobrupakroy
Some of my alternative internet presences are Facebook, Instagram, Udemy, Blogger, Issuu, Slideshare, Scribd, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Let me know if you need anything. Talk Soon.


Comments
Post a Comment