Introduction to the Various Types of Adapters in Large Language Models (LLMs)
Explore LLM adapters to improve the efficiency of the LLMS
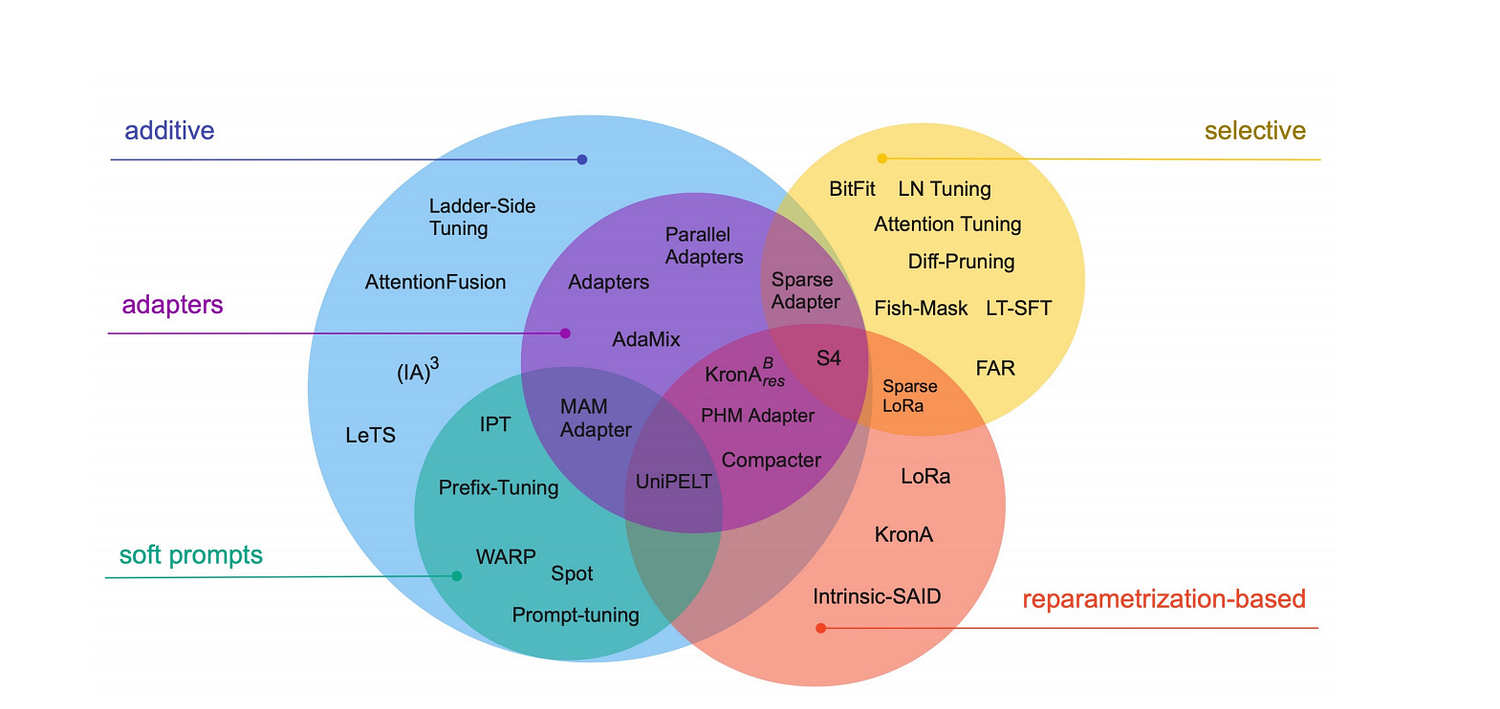
In recent years, adapters have emerged as a crucial technique for improving the efficiency of Large Language Models (LLMs). These methods allow for fine-tuning models in a way that’s parameter-efficient while maintaining or improving performance for specific tasks. Below, we’ll explore the different types of adapters commonly used in LLMs and how they enhance the model’s adaptability.
1. Standard Adapters
- Overview: Introduced as a method for parameter-efficient fine-tuning, standard adapters involve adding small, fully connected layers (or modules) between the layers of a pre-trained model. These adapters are trained for specific tasks while keeping the main model parameters frozen, minimizing computational overhead.
- Use case: Useful for adapting large, pre-trained models to new domains or tasks without retraining the entire model. Commonly used in applications like NLP, computer vision, and multi-domain transfer learning.
2. Parallel Adapters
- Overview: These adapters operate in parallel to the main transformer layers. Instead of sequentially inserting adapters after every layer, parallel adapters run alongside, offering more flexibility in model architecture.
- Use case: Effective for tasks that require more diverse representations and multi-modal data processing, such as combining text, images, or speech.
3. Sparse Adapters
- Overview: Sparse adapters use a sparse configuration to reduce the number of parameters further. Only a fraction of the neurons is activated during the forward pass, optimizing memory and computational usage.
- Use case: Ideal for large-scale deployment in resource-constrained environments where efficiency and speed are key, such as mobile and embedded devices.
4. AdapterFusion
- Overview: This method allows for the fusion of multiple pre-trained adapters to improve performance on multi-task learning. AdapterFusion trains small layers on top of several adapters to determine the best combination of task-specific knowledge.
- Use case: Particularly useful when dealing with multi-task scenarios, where a single model must perform well across several domains or tasks, such as multi-lingual text processing.
5. Compacter
- Overview: The Compacter method builds on standard adapters by using Kronecker product-based reparameterization to reduce the number of parameters even further. This method leverages low-rank factorization to maximize parameter efficiency.
- Use case: Excellent for scenarios requiring extreme efficiency, such as real-time processing or deploying models on edge devices with limited hardware resources(2303.15647v1).
6. BitFit
- Overview: BitFit only tunes the bias terms of the model, while keeping the rest of the parameters frozen. It’s a highly parameter-efficient method that requires updating just a tiny portion of the model.
- Use case: Best for low-resource tasks where only minimal fine-tuning is required, such as few-shot learning or when memory limitations are strict.
7. Prefix-Tuning
- Overview: This method prepends learnable vectors (prefixes) to the input sequences of all layers, fine-tuning the model’s behavior in a task-specific way. Prefix-Tuning is highly efficient because it avoids modifying the model’s main parameters.
- Use case: Used extensively in text generation and dialogue models, where task-specific tuning is needed without retraining large models from scratch.
I hope this helps!
NExt, Evaluating RAG Models with ARES: A Scalable Approach to Automated Retrieval and Generation Scoring.
ARES (Automated Retrieval-Enhanced Scoring) is an evaluation framework designed to assess the performance of…bobrupakroy.medium.com
Thanks for your time, if you enjoyed this short article there are tons of topics in advanced analytics, data science, and machine learning available in my medium repo. https://medium.com/@bobrupakroy
Some of my alternative internet presences are Facebook, Instagram, Udemy, Blogger, Issuu, Slideshare, Scribd, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy



Comments
Post a Comment