Mastering RAG Fusion in Simple Steps: A Deep Dive into Retrieval-Augmented Generation"
Revolutionize the way we approach natural language processing and information retrieval. We delve into the intricacies of RAG Fusion, exploring the mechanics behind this innovative approach.

Hi everyone today we will look into some custom “you may call it advanced” hybrid approaches in retrieving the documents.
We all know what is Retrieval-Augmented Generation (RAG) ?
is the process of optimizing the output of a large language model, so it references an authoritative knowledge base outside of its training data sources before generating a response.
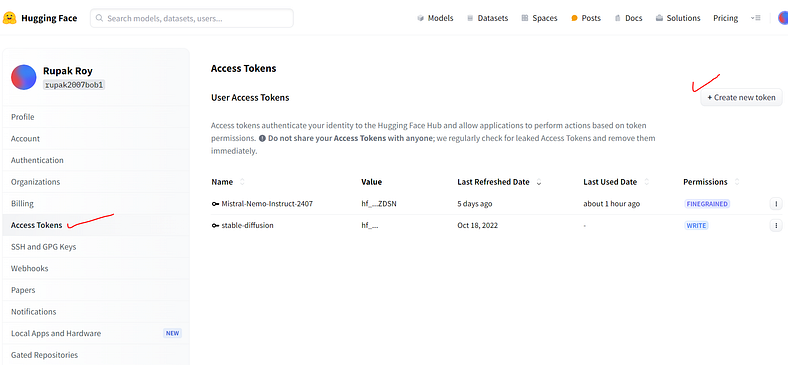
Let’s start with our legacy techniques, but before that likewise we will set up the LLM environment from hugging face model API calls which provide better token limits than open ai.
First login to the Hugging face and generate the API key(Access Token)
#######################################################
#Step up the LLM Environment
#######################################################
from langchain_community.llms.huggingface_endpoint import HuggingFaceEndpoint
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains.mapreduce import MapReduceChain
##################################################
#Model API call
repo_id = "mistralai/Mistral-7B-Instruct-v0.2"
llm = HuggingFaceEndpoint(
repo_id=repo_id,
max_length=128,
temperature=0.5,
huggingfacehub_api_token= "hf_yourkey")Legacy Approach includes
Text split > Create/Load Vector Store > RetrievalQA Chain
##########################################
### Legacy: RAG Approach #################
##########################################
#pip install pypdf
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter,RecursiveCharacterTextSplitter
#Load Multiple pdf
from langchain_community.document_loaders import PyPDFDirectoryLoader
loader = PyPDFDirectoryLoader("F:\MLwithpython\LLM\documents_rag/")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=64)
texts = text_splitter.split_documents(documents)
################################################
############ CREATE Vector Store ###############
################################################
#-------------CREATE Vector EMBEDINGS------------------------------------
#----------- Load the Embedding model ---------------------
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
model_name = "sentence-transformers/all-mpnet-base-v2"
model_kwargs = {"device": "cpu"}
embeddings = HuggingFaceEmbeddings(model_name=model_name, model_kwargs=model_kwargs)
#-------------Create Vector Store--------------------------
# Use FAISS vector DB
from langchain.vectorstores.faiss import FAISS
vc_db = FAISS.from_documents(texts, embeddings)
vc_db.save_local("faiss_index")
vc_db = FAISS.load_local("faiss_index", embeddings,allow_dangerous_deserialization=True)
############### Retrival ########################
##################################################
#Initialize the retrievaer
# retriever = vectordb.as_retriever(search_kwargs={"k": 3})
retriever = vc_db.as_retriever()
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
verbose=True)
results = qa.invoke("summarize the document in 10 bullets")
results['result']
#approach 2
def test_rag(qa, query):
print(f"Query: {query}\n")
result = qa.run(query)
print("\nResult: ", result)
query = "What were the main topics in the State of the Union in 2023? Summarize. Keep it under 200 words."
test_rag(qa, query)
#document search
docs = vc_db.similarity_search(query)
print(f"Query: {query}")
print(f"Retrieved documents: {len(docs)}")
for doc in docs:
doc_details = doc.to_json()['kwargs']
print("Source: ", doc_details['metadata']['source'])
print("Text: ", doc_details['page_content'], "\n")Now let’s try with Fusion Techniques.
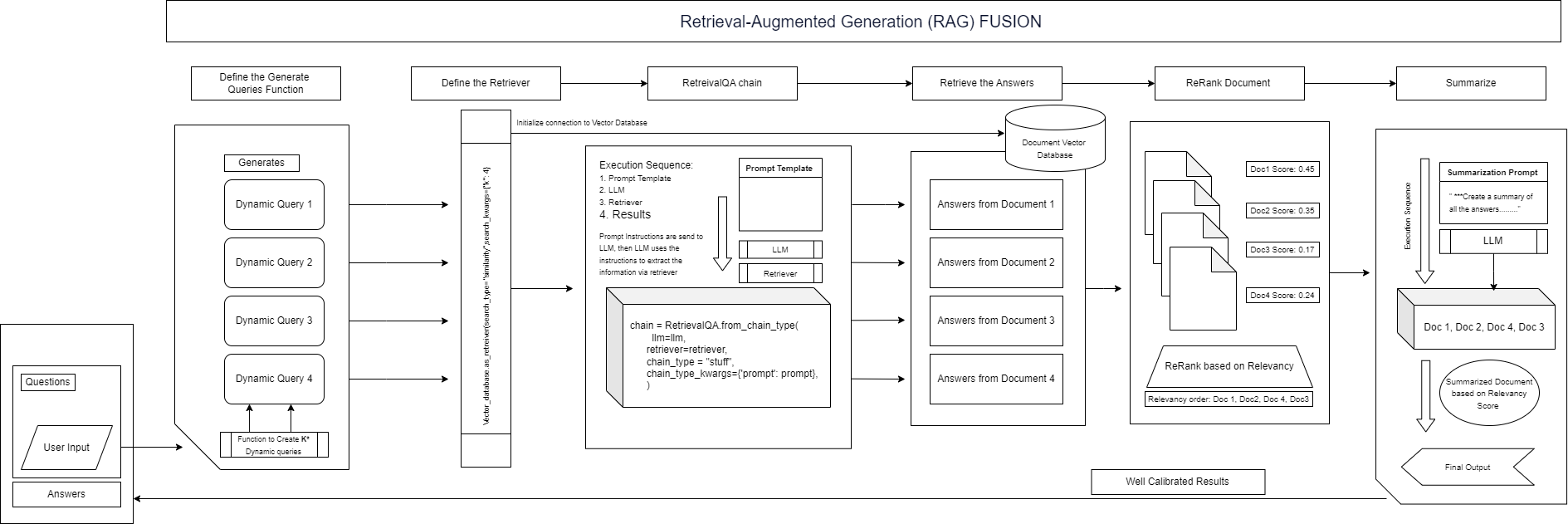
RAG Fusion FlowDiagram that we will follow
#internal query generation-------------------
def generate_queries(model,prompt, num_queries):
from langchain.prompts import ChatPromptTemplate
query_generation_prompt = ChatPromptTemplate.from_template(
"""Given the prompt: '{prompt}', generate {num_queries} questions that are better articulated.
Return in the form of an list. For example: ['question 1', 'question 2', 'question 3']""")
query_generation_chain = query_generation_prompt | model
#return str_to_json(query_generation_chain.invoke({"prompt": prompt, "num_queries": num_queries}).content)
return query_generation_chain.invoke({"prompt": prompt, "num_queries": num_queries})
#---------------------------------------------------------
original_query = "impact of climate change"
original_query2 = "summerize me the terms and conditions"
#generate internal queries ----------------------------
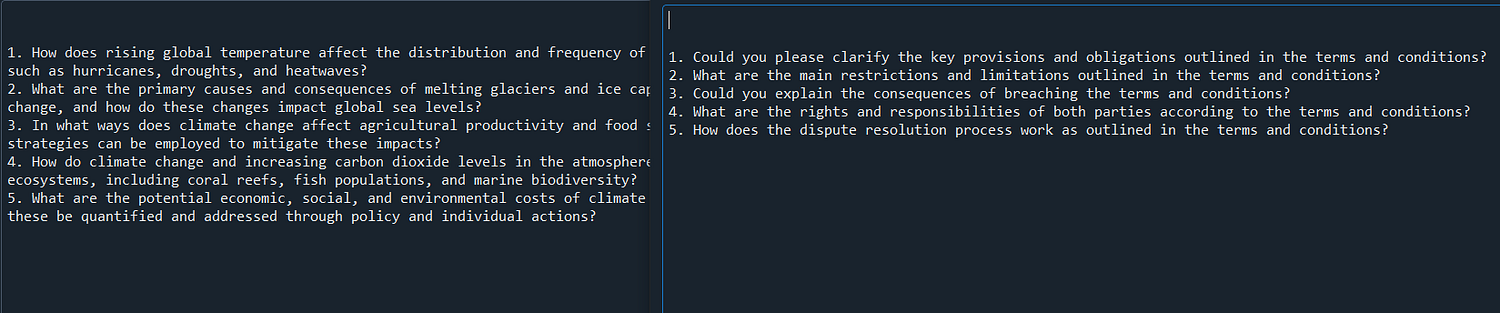
generated_queries = generate_queries(llm, original_query,5)
generated_queries2 = generate_queries(llm, original_query2,5)Testing the function “generate_queries” is able to generate 5 multiple queries to its original queries.
Now we will create the retriever
##################################################
# using a Langchain ##############################
##################################################
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.retrievers import ReRankerRetriever
from langchain.prompts import PromptTemplate
'
#load the vector db we already created above
vc_db = FAISS.load_local("faiss_index", embeddings,allow_dangerous_deserialization=True)
retriever = vc_db.as_retriever(search_type="similarity",search_kwargs={"k": 4})
#other search_type:
#search_type="similarity_score_threshold", search_kwargs={"score_threshold": 0.5}
#db.as_retriever(search_type="mmr")} #Maximum marginal relevance retrieva
retreiver_1 = vc_db.as_retriever(search_type="similarity_score_threshold",
search_kwargs={'score_threshold': 0.2})
docs2 = retriever.invoke("What are the terms and conditions") #retreiver search
docs22 = retriever.invoke("get me the price of icecream") ##retreiver search
docs3 = vc_db.similarity_search("What are the terms and conditions",search_kwargs={"k": 4})#similarity search
docs33 = vc_db.similarity_search("get me the price of icecream",search_kwargs={"k": 4})
#more stricker at the same time we are lossing the semantic meaning
docs31 = retreiver_1.invoke("get me the price of icecream")
docs311 = retreiver_1.invoke("What are the terms and conditions")
Both of them work same so don't get confused retriever is just a wrapper function that includes search_type = “Similarity” and we also observe it gave answer/fletch non-correlated information even though it is not in the vector db.
docs31 will have no results and docs311 will have 3 or less documents.
Back to our original generated internal queries + retriever
#BACK TO our original generated internal queries -----------
#using: generated_queries = generate_queries(llm, query,5)
generated_queries
generated_queries2
docs4 = vc_db.similarity_search(generated_queries,search_kwargs={"k": 4})
docs5 = vc_db.similarity_search(generated_queries2,search_kwargs={"k": 4})
# Helper function for printing docs
def pretty_print_docs(docs):
print(
f"\n{'-' * 100}\n".join(
[f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(docs)]
)
)
pretty_print_docs(docs4)
pretty_print_docs(docs5)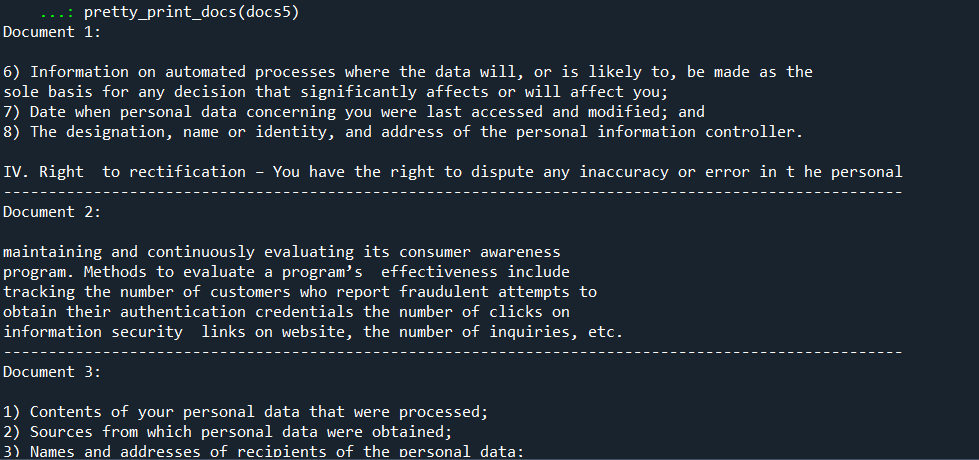
print(f"Query:{generated_queries2}")
print(f"Retrieved documents: {len(docs5)}")
for doc in docs5:
doc_details = doc.to_json()['kwargs']
print("Source: ", doc_details['metadata']['source'])
print("Text: ", doc_details['page_content'], "\n")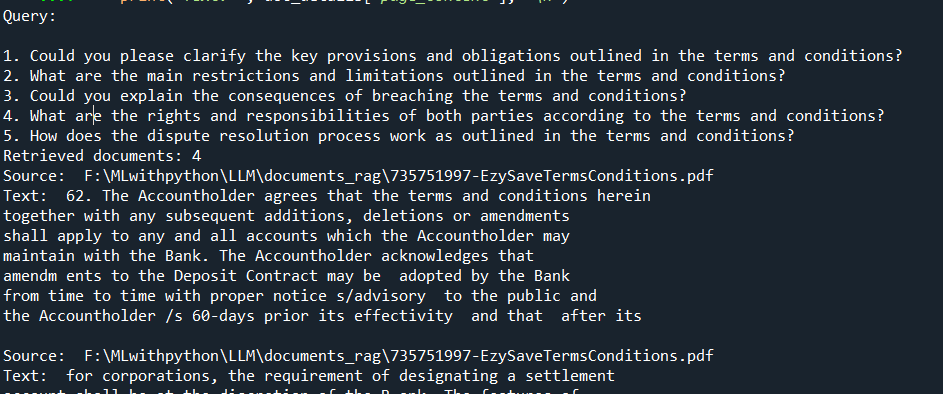
Now we will set the final Retrieval Chain
#################################################
# Set the final RetreivalQA chain ###############
#################################################
#adding prompt for RetreivalQA to stop answering/suggesting general information
from langchain.prompts import PromptTemplate
template = """Answer the question in your own words from the
context given to you.
If questions are asked where there is no relevant context available, please answer
"i apologize i cant answer" and dont give any suggestions, guidance or any general information of the Context
Context: {context}
Human: {question}
"""
prompt = PromptTemplate(input_variables=["context","question"], template=template)
llm = llm #already intialized above
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever, #drawback misses semantic meaning leads to wrong information
chain_type = "stuff",
chain_type_kwargs={'prompt': prompt},
)
query = "Tell me about ice creams."
result = chain.invoke({"query": "tell me about climate change, tell me about llm, how to catch fish?"})
print(result)
result1 = chain.invoke({"query": generated_queries})
print(result1)
result2 = chain.invoke({"query": generated_queries2})


One thing we have noticed in result2 it still gives suggestions, general information from the LLM engine. Thus to avoid this we can try adding more templates into prompt engineering.
Another approach is to create Agents and tools
Now we will consolidate the answers into one.
#+++++++++++++++++++++++++++++++++++++++++++++++++++
#Consolidating the answers generated by multiple queries(generated_queries) for caliberated results
from langchain.prompts import ChatPromptTemplate
first_prompt1 = ChatPromptTemplate.from_template(
"""You are an expert who provides 80 words detailed answers of{context} in bullets based on the provided context.
Context: {context}
Answer: summerize it
"""
)
chain_two1 = first_prompt1 | llm
t3 = chain_two1.invoke({"context": result2["result"]}) #context
t33 = chain_two1.invoke({"context": result1["result"]})
t333 = chain_two1.invoke({"context": result2["result"]}) 
Alternatively, using runnable
#Alternatively
#using Runnables
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
setup_and_retrieval = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()} )
chain_three = setup_and_retrieval | prompt | llm
t5=chain_three.invoke("tell me the terms and conditions")
t4 = chain_three.invoke("how can i cook food", #multi queries: terms & conditions of bank
) Adding the Reciprocal Rank Fusion (RRF)
#############################################
# ReRanking #################################
#############################################
#Pseudo-code implementation of RRF (available in the web)
function calculateRRF(rankings, k):
scores = {}
for each document d:
scores[d] = 0
for each ranker r:
rank = rankings[r][d]
scores[d] += 1 / (k + rank)
return scores
function getFinalRanking(scores):
return sort documents by scores in descending orderThere are tons of ways to create ranks based on relevancy, also there is many models already available namely #CohereAI
#bge-reranker-base
#bge-reranker-large.
My personal suggestion is to make own sentence similarity techniques like cosine and rank it because at a production we might not be getting internet access or any third party integration. i will update this article with a solution soon.
Summary, workflow ~
Next, we will try to add tools and Agents in the advancement of RAG FUSION and Evaluate RAG using RAGAS, ARES and more until then stay tuned.
Thanks for your time, if you enjoyed this short article there are tons of topics in advanced analytics, data science, and machine learning available in my medium repo. https://medium.com/@bobrupakroy
Some of my alternative internet presences are Facebook, Instagram, Udemy, Blogger, Issuu, Slideshare, Scribd, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Let me know if you need anything. Talk Soon.
Check out the links i hope it helps.


Comments
Post a Comment