Comprehensive 10+ LLM Evaluation: From BLEU, ROUGE, and METEOR to Scenario-Based Metrics like Responsible AI, Text-to-SQL, Retrieval Q&A, and NER
In this in-depth article, we explore the evaluation of over 10 leading Large Language Models (LLMs) using a range of metrics, including traditional methods like BLEU, ROUGE, and METEOR, alongside scenario-based metrics tailored for specific applications. We dive into Responsible AI, Text-to-SQL metrics, Retrieval Q&A, Named Entity Recognition (NER), and guardrails, providing a comprehensive guide to understanding and comparing LLM performance across diverse tasks. Whether you’re a researcher, developer, or enthusiast, this article offers valuable insights into the best practices for evaluating the capabilities of today’s top LLMs.

We will start with the commonly used metrics named BLEU SCORE, ROUGE SCORE, METEOR, and much more.
Before we get started we will likewise we will load our environment using Huggingface model API calls which provide better token limits than open ai.
First login to the Hugging face and generate the API key(Access Token)
#######################################################
#Step up the LLM Environment
#######################################################
from langchain_community.llms.huggingface_endpoint import HuggingFaceEndpoint
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains.mapreduce import MapReduceChain
##################################################
#Model API call
repo_id = "mistralai/Mistral-7B-Instruct-v0.2"
llm = HuggingFaceEndpoint(
repo_id=repo_id,
max_length=128,
temperature=0.5,
huggingfacehub_api_token= "hf_yourkey")BLEU SCORE(Bilingual Evaluation Understudy)
The BLEU (Bilingual Evaluation Understudy) score is a metric used to evaluate the quality of text generated by language models, particularly in machine translation. It measures how closely the generated text matches a set of reference translations or texts.
We will install the required package ‘evaluate’ which contains BLEU metric
#Example 1
#pip install evaluate
#pip install langkit[all]
from langkit.whylogs.samples import load_chats
chats = load_chats() #pre-build chat samples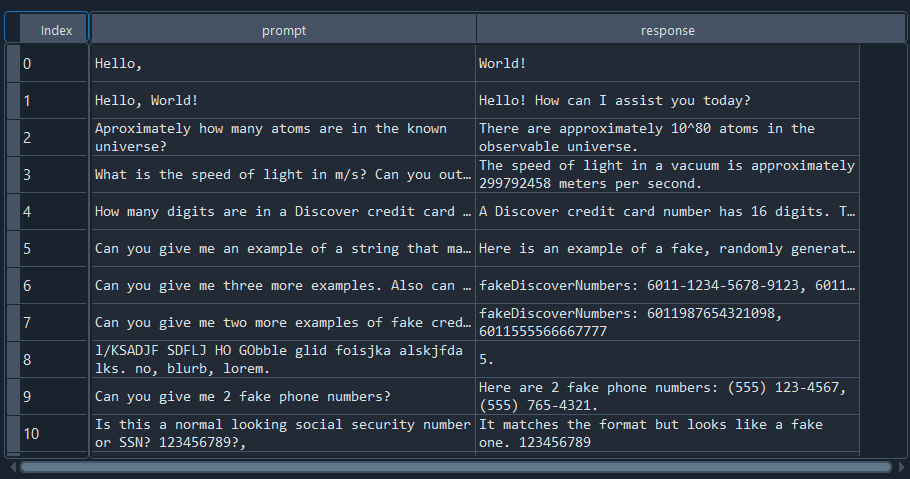
Then,
import evaluate
bleu = evaluate.load("bleu")
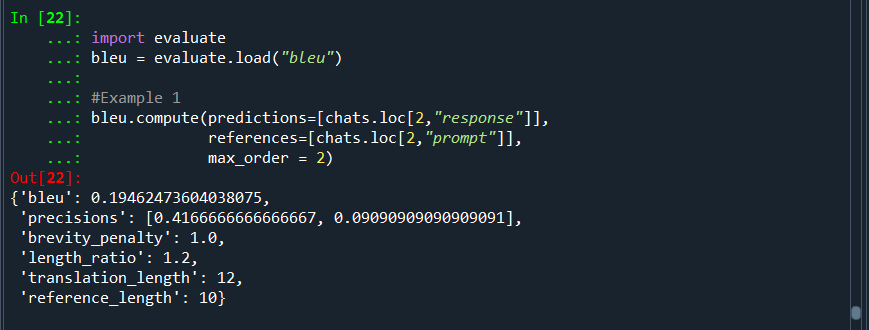
#Example 1
bleu.compute(predictions=[chats.loc[2,"response"]],
references=[chats.loc[2,"prompt"]],
max_order = 2)Where,
- predictions (list of strs): Translations to score.
- references (list of lists of strs): references for each translation.
- ** tokenizer** : approach used for standardizing predictions and references. The default tokenizer is tokenizer_13a, a relatively minimal tokenization approach that is however equivalent to mteval-v13a, used by WMT. This can be replaced by another tokenizer from a source such as SacreBLEU. The default tokenizer is based on whitespace and regexes. It can be replaced by any function that takes a string as input and returns a list of tokens as output. E.g. word_tokenize() from NLTK or pretrained tokenizers from the Tokenizers library.
- max_order (int): Maximum n-gram order to use when computing BLEU score. Defaults to 4.
- smooth (boolean): Whether or not to apply Lin et al. 2004 smoothing. Defaults to False.
Output Values interpretation:
#BLEU’s output is always a number between 0 and 1. This value indicates how similar the candidate text is to the reference texts, with values closer to 1 representing more similar texts.
#Try out with tokenizer
#Example 2: BLEU Score with the word tokenizer from NLTK:
bleu = evaluate.load("bleu")
from nltk.tokenize import word_tokenize
predictions = ["hello there general kenobi"]
references = ["hello there general kenobi hi hello"]
results = bleu.compute(predictions=predictions, references=references)
print(results)
results = bleu.compute(predictions=[chats.loc[2,"response"]], references=[chats.loc[2,"prompt"]], tokenizer=word_tokenize)
print(results)How it is calculated?
BLEU Score = BP(Brevity Penalty*exp(∑ pn)
where,
pn is the precision of n-grams, which is calculated as the number of n-grams that appear in both the machine-generated translation and the reference translations divided by the total number of n-grams in the machine-generated translation.
BP(Brevity Penalty) is a penalty term that adjusts the score for translations that are shorter than the reference translations. It is calculated as min(1, (reference_length / translated_length)), where reference_length is the total number of words in the reference translations, and translated_length is the total number of words in the machine-generated translation.)
- To prevent the model from generating very short sentences that might have high precision (e.g., “The cat” as a translation for “The cat is on the mat”), BLEU includes a brevity penalty.
- This penalty reduces the score if the candidate text is shorter than the reference text, encouraging models to generate outputs of appropriate length.
What is n-grams?
BLEU evaluates the overlap between n-grams (sequences of n words) in the generated text (candidate) and the reference texts.
Commonly used n-grams include unigrams (single words), bigrams (pairs of words), trigrams (triples of words), and so on.
For example, if the reference text is “The cat is on the mat” and the candidate text is “The cat sits on the mat,” the BLEU score would look at the overlap between these sequences at different n-gram levels.
So How BLEU Score Works:
N-gram Matching:
BLEU evaluates the overlap between n-grams (sequences of n words) in the generated text (candidate) and the reference texts.
Commonly used n-grams include unigrams (single words), bigrams (pairs of words), trigrams (triples of words), and so on.
For example, if the reference text is “The cat is on the mat” and the candidate text is “The cat sits on the mat,” the BLEU score would look at the overlap between these sequences at different n-gram levels.
Precision Calculation:
BLEU calculates the precision for each n-gram level, which is the proportion of n-grams in the candidate text that appears in the reference texts.
Precision is computed for unigrams, bigrams, trigrams, etc., up to a certain maximum n-gram level (usually 4-grams).
Remeber precision in machine learning terminology is Quality of the model. Quality of the model predicted True Positive is actually Positive.
Weighted Average of Precision:
The BLEU score then takes a weighted average of these precisions across different n-gram levels.
Typically, equal weights are assigned to each n-gram level, though this can be adjusted depending on the specific application.
Brevity Penalty:
To prevent the model from generating very short sentences that might have high precision (e.g., “The cat” as a translation for “The cat is on the mat”), BLEU includes a brevity penalty.
This penalty reduces the score if the candidate text is shorter than the reference text, encouraging models to generate outputs of appropriate length.
Final BLEU Score:
The final BLEU score is calculated as the geometric mean of the weighted precisions multiplied by the brevity penalty.
The score ranges from 0 to 1, where 1 indicates a perfect match between the candidate and reference texts, and 0 indicates no match.
Formula:
The BLEU score is calculated using the following formula:
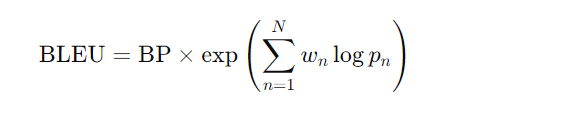
Limitations and Bias:
- Lack of Semantic Understanding: BLEU primarily focuses on exact word matches and may not fully capture the semantic meaning of the text. It may penalize paraphrases or rewordings that convey the same meaning as the reference.
- Shorter predicted translations achieve higher scores than longer ones, simply due to how the score is calculated. A brevity penalty is introduced to attempt to counteract this.
- BLEU score varies heavily based on factors like number of references, normalization and tokenization techniques etc., For this reason it is difficult to use them for comparison across datasets that use different techniques.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) Score
The ROUGE (Recall-Oriented Understudy for Gisting Evaluation) score is another widely used metric for evaluating the quality of text generated by language models, especially in tasks like text summarization.
Unlike BLEU, which focuses on precision (the proportion of generated content that matches the reference), ROUGE emphasizes recall (the proportion of reference content that is captured in the generated text).
Types of ROUGE Scores
There are several variants of the ROUGE score, each focusing on different aspects of text similarity:
1. ROUGE-N
- Focus: N-gram overlap between the generated text and the reference text.
- How it works: Measures the recall of n-grams (sequences of
nwords) in the generated text compared to the reference text. - Common variants:
- ROUGE-1: Unigram (single word) overlap.
- ROUGE-2: Bigram (two-word) overlap.
- Example: If the reference text is “The cat is on the mat” and the generated text is “The cat sat on the mat,” ROUGE-1 would count the overlap of individual words like “The,” “cat,” and “mat.”
2. ROUGE-L
- Focus: Longest Common Subsequence (LCS) between the generated and reference texts.
- How it works: Measures the longest sequence of words that appears in both the generated and reference texts in the same order. This captures sentence-level structure and coherence.
- Example: For the reference “The cat is on the mat” and the generated “The cat sat on the mat,” the LCS is “The cat on the mat.”
3. ROUGE-W
- Focus: Weighted Longest Common Subsequence (WLCS).
- How it works: Similar to ROUGE-L, but gives more weight to longer matches, rewarding models that generate longer, contiguous sequences of matching words.
4. ROUGE-S (ROUGE-Skip or ROUGE-Sentence)
- Focus: Skip-bigram overlap.
- How it works: Measures the overlap of pairs of words in the generated and reference texts, allowing for gaps between the words. It’s less strict than ROUGE-N and can capture more flexible matches.
- Example: For “The cat is on the mat” and “The cat sat on the mat,” ROUGE-S would consider pairs like (“The”, “on”) and (“cat”, “mat”).
How ROUGE Works
- Recall Calculation:
- ROUGE primarily focuses on recall, calculating the proportion of overlapping n-grams or sequences in the reference text that are captured by the generated text.
- Precision and F1-Score:
- While recall is the focus, ROUGE can also consider precision (like BLEU does) and compute an F1-score, which balances both precision and recall.
ROUGE is particularly popular in text summarization tasks.
Limitations of ROUGE
- Lack of Semantic Understanding: Like BLEU, ROUGE relies on exact word or sequence matches and may not fully capture the semantic equivalence between the generated and reference texts.
- Sensitivity to Wording: ROUGE might penalize valid paraphrases or rewordings that convey the same meaning as the reference but use different words.
- Overemphasis on Recall: ROUGE focuses on recall, which might not always be ideal, especially in tasks where conciseness and precision are also important.
###########################################################################
# ROUGE (Recall-Oriented Understudy for Gisting Evaluation) Score #########
###########################################################################
#pip install rouge_score
# Load the ROUGE evaluation metric
rouge = evaluate.load('rouge')
#Example 1
rouge.compute(predictions=[chats.loc[2,"response"]],
references=[chats.loc[2,"prompt"]],
)
#rouge1: 1-gram/Unigram overlap between the generated text and the reference text.
#rouge2: 2-gram/Bigram overlap between the generated text and the reference text.
#rougeLsum: refers it is computed over the entire summary,
#rougeL: is computed as an average over individual sentences.
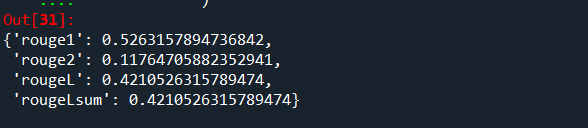
Output values interpretation:
ROUGE metrics range between 0 and 1, with higher scores indicating higher similarity between the automatically produced summary and the reference.
ROUGE SCORE VS BLEU
1. Focus
- BLEU (Bilingual Evaluation Understudy)
Focus on Precision: BLEU primarily measures precision, which means it evaluates how much of the generated text matches the reference text. It checks for n-gram overlaps, emphasizing how many of the n-grams in the generated output appear in the reference.
Use Case: Commonly used in machine translation and other tasks where generating text that closely matches a reference in terms of word choice and order is crucial.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
Focus on Recall: ROUGE emphasizes recall, assessing how much of the reference text is captured in the generated text. It also considers n-gram overlaps, but the key metric is how much of the reference’s information is retained.
Use Case: Widely used in text summarization and tasks where capturing the full content of the reference text is more important than the exact word order or choice.
2. Strengths
- BLEU:
Precision-oriented: Effective in scenarios where exact matches to the reference are important.
Penalizes overly short outputs: The brevity penalty helps prevent models from generating short outputs that might have high precision but miss much of the content.
- ROUGE:
Recall-oriented: Ideal for tasks where capturing the full scope of content is more important, such as summarization.
Flexibility in Matching: ROUGE-L and ROUGE-S allow for more flexible matching that can account for different word orders and structures.
3. Limitations
- BLEU:
Insensitive to synonyms and paraphrasing: BLEU may penalize valid paraphrases or synonyms, as it only looks for exact n-gram matches.
Less effective for longer text: The precision-based approach can struggle with long, complex outputs where multiple correct answers exist.
- ROUGE:
Recall bias: ROUGE’s focus on recall might lead to higher scores for outputs that are longer or include more of the reference content, even if they are less precise.
Limited semantic understanding: Like BLEU, ROUGE doesn’t account for the semantic meaning of the text, focusing instead on surface-level matches.
4. Interpreting Scores
- BLEU: A higher BLEU score indicates that the generated text has a high overlap with the reference text in terms of n-grams, but it may not fully capture all the important content if the model is overly focused on precision.
- ROUGE: A higher ROUGE score suggests that the generated text includes more of the content from the reference, but it may also indicate redundancy or less concise output if the model prioritizes recall.
BLEU is more suitable for tasks where exact matching with the reference text is crucial, such as in machine translation usecases where the exact wording and structure are critical also in tasks where generating text that closely mimics a reference is important, such as in automatic captioning. ROUGE is better suited for tasks where capturing the content or gist of the reference text is important, such as in summarization, document comparison or evaluating the informativeness of generated content.
Metric for Evaluation of Translation with Explicit Ordering (METEOR)
METEOR score is a metric that measures the quality of generated text based on the alignment between the generated text and the reference text particularly in machine translation and other text generation tasks. It was designed to address some of the limitations of the BLEU score by incorporating more sophisticated linguistic features
Key Features of METEOR:
1. Harmonic Mean of Precision and Recall:
- Precision and Recall: Unlike BLEU, which focuses primarily on precision, METEOR computes both precision and recall and then combines them into a single score. The combination is done using the harmonic mean, with recall typically weighted higher than precision.
- Harmonic Mean: This approach balances the need to produce text that matches the reference closely (precision) while also ensuring that as much of the reference text’s content is captured as possible (recall).
2. Linguistic Features:
- Synonymy: METEOR includes mechanisms to match words that are synonyms, not just exact matches, using resources like WordNet. This helps it recognize when different words convey the same meaning.
- Stemming: The metric uses stemming to match words that share the same root form (e.g., “run” and “running”).
- Paraphrasing: METEOR can match paraphrases or variations in phrasing that convey the same meaning, making it more semantically aware than BLEU.
3. Alignment:
- Chunk-based Matching: METEOR attempts to align the words in the generated text with the reference text. It does this by identifying chunks of words that match, both in terms of content and order. A penalty is applied for any reordering of chunks, which encourages the generation of text with a similar structure to the reference.
4. Penalty for Fragmentation:
- Fragmentation Penalty: If the generated text has matching words that are scattered and not in contiguous sequences, METEOR applies a penalty. This discourages disjointed translations and favors those that maintain a more coherent structure.

Advantages of METEOR:
- Semantic Awareness: By including synonymy, stemming, and paraphrasing, METEOR is better at recognizing the true meaning of text, beyond just exact word matches.
- Balanced Evaluation: The use of both precision and recall, along with a penalty for fragmentation, provides a more balanced evaluation of text quality compared to BLEU.
- Better Correlation with Human Judgments: Studies have shown that METEOR often correlates more closely with human judgments of translation quality than BLEU, making it a valuable metric in machine translation.
Limitations of METEOR:
- Computational Complexity: METEOR is more computationally intensive than BLEU due to its reliance on linguistic resources like synonym dictionaries and stemming algorithms.
- Dependence on Linguistic Resources: The quality of the METEOR score can depend on the comprehensiveness of the synonym and stemming resources available for the language in question.
- Language-Specific: While METEOR is effective in English and some other languages with well-developed linguistic resources, it may be less effective in languages where such resources are lacking.
Common Applications are Machine Translation, Text Summerization, Paraphrasing
The METEOR score is a powerful and linguistically informed metric for evaluating text generated by language models. It addresses many of the limitations of BLEU by incorporating semantic understanding, making it particularly useful in tasks where capturing the true meaning of the text is essential. Thus provides a more accurate reflection of text quality.
import numpy as np
from nltk.translate.meteor_score import single_meteor_score
reference = ["this is an apple", "that is an apple"]
model = ["an apple on this tree"]
reference1 = ["this is an apple but good"]
score = single_meteor_score(reference, model)
score1 = single_meteor_score(reference1, model)
print(np.mean(score))
print(score1)Another way
import re
from collections import Counter
def tokenize(text):
"""Basic tokenizer that splits text into words."""
return re.findall(r'\w+', text.lower())
def precision_recall(candidate, reference):
"""Calculate precision and recall based on token overlap."""
candidate_tokens = tokenize(candidate)
reference_tokens = tokenize(reference)
candidate_count = Counter(candidate_tokens)
reference_count = Counter(reference_tokens)
# Count matches
overlap = sum(min(candidate_count[token], reference_count[token]) for token in candidate_count)
precision = overlap / len(candidate_tokens)
recall = overlap / len(reference_tokens)
return precision, recall, overlap
def fragmentation_penalty(matches, candidate_tokens):
"""Calculate the penalty for fragmented matches."""
chunks = 1
for i in range(1, len(matches)):
if matches[i] != matches[i-1] + 1:
chunks += 1
penalty = 0.5 * (chunks / matches.count(True))
return penalty
def meteor_score(candidate, reference):
"""Compute the METEOR score."""
candidate_tokens = tokenize(candidate)
reference_tokens = tokenize(reference)
# Calculate precision and recall
precision, recall, overlap = precision_recall(candidate, reference)
# Harmonic mean of precision and recall
if precision + recall == 0:
f_score = 0
else:
f_score = (10 * precision * recall) / (recall + 9 * precision)
# Find matching positions
matches = []
ref_pos = 0
for token in candidate_tokens:
if token in reference_tokens[ref_pos:]:
matches.append(reference_tokens[ref_pos:].index(token) + ref_pos)
ref_pos = matches[-1] + 1
else:
matches.append(None)
# Fragmentation penalty
penalty = fragmentation_penalty(matches, candidate_tokens)
# Final METEOR score
meteor = f_score * (1 - penalty)
return meteor
# Example usage
reference_text = "The quick brown fox jumps over the lazy dog."
generated_text = "A fast brown fox leaped over a lazy dog."
score = meteor_score(generated_text, reference_text)
print(f"METEOR score: {score:.4f}")
#output
#METEOR score: 0.6667Explanation of the Code:
1. Tokenization (tokenize):
- The
tokenizefunction splits the input text into words, converting everything to lowercase for case-insensitive comparison.
2. Precision and Recall Calculation (precision_recall):
- This function calculates the precision and recall based on the overlap of tokens between the candidate (generated) text and the reference text.
3. Fragmentation Penalty Calculation (fragmentation_penalty):
- The
fragmentation_penaltyfunction calculates a penalty for disjointed matches by counting the number of chunks (consecutive matching tokens) in the candidate text.
4. METEOR Score Calculation (meteor_score):
- This is the main function that computes the METEOR score using precision, recall, harmonic mean, and the fragmentation penalty.
Thats it done!
There are other new approaches that suits different types of complex uses cases.
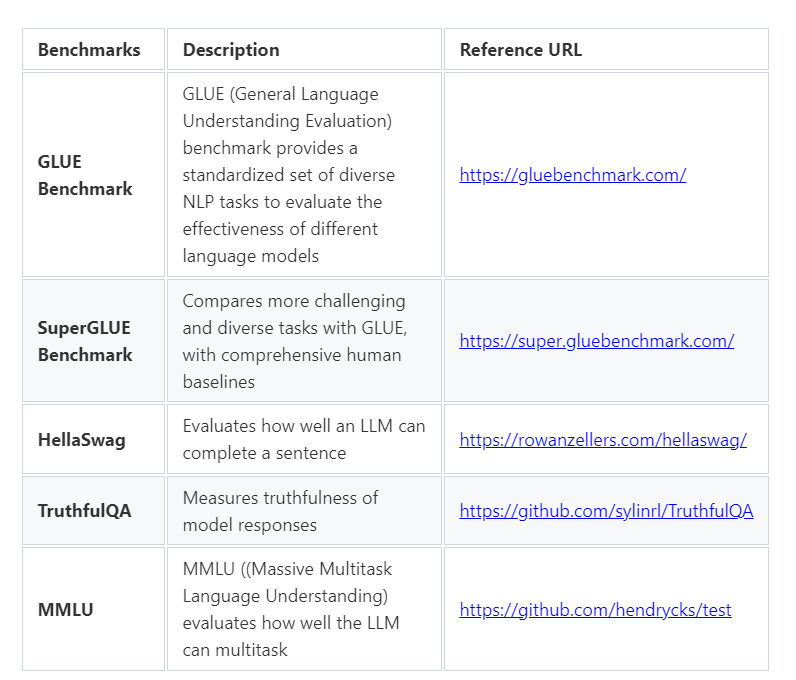
Sample LLM model evaluation benchmarks.
Sample evaluation frameworks
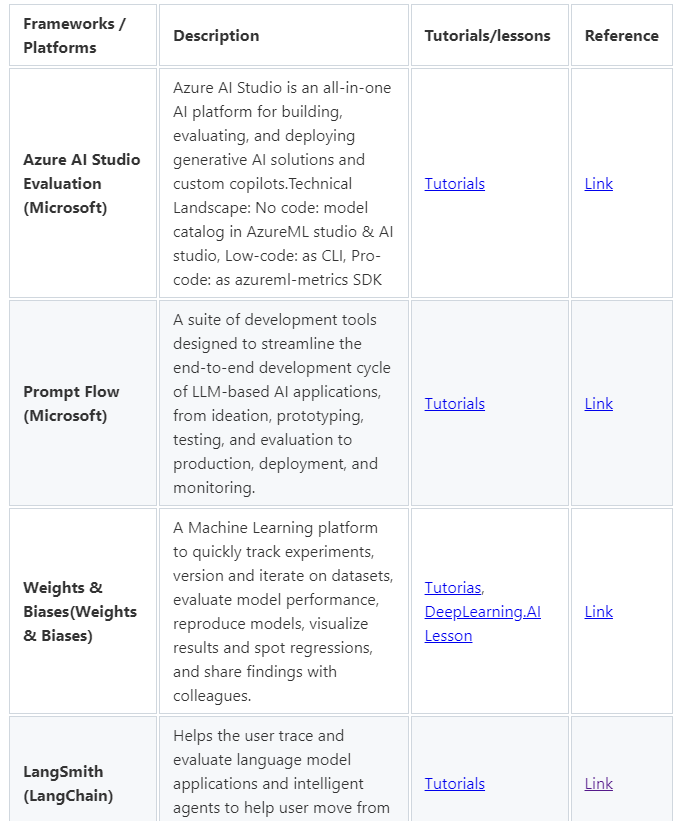
Online and Offline Evaluations
includes golden datasets, supervised learning, and human annotation etc.
Ai Evaluating Ai
tempplate = [
"Instruction:
You are an AI evaluator tasked with assessing the accuracy of another AI's performance.\
You will be given a task, the input text, the AI's output, and the correct output. \
Your job is to assign a numeric score between 0 and 1, where 1 indicates perfect accuracy \,
and 0 indicates complete inaccuracy. Please provide only the numeric score based on the comparison \
between the AI's output and the correct output.
Task: Sentiment Analysis
Input Text: "I absolutely love this product! It's amazing!"
AI's Output: Positive
Correct Output: Positive
Score: 1
Task: Sentiment Analysis
Input Text: "This movie was terrible, I hated every minute of it."
AI's Output: Neutral
Correct Output: Negative
Score: 0
Task: Entity Extraction
Input Text: "Apple Inc. was founded by Steve Jobs, Steve Wozniak, and Ronald Wayne."
AI's Output: Steve Jobs, Steve Wozniak
Correct Output: Steve Jobs, Steve Wozniak, Ronald Wayne
Score: 0.67
Task: Text Classification
Input Text: "Breaking: The stock market crashes by 20% in a single day."
AI's Output: Finance
Correct Output: Finance
Score: 1
Task: Entity Extraction
Input Text: "The headquarters of Microsoft is located in Redmond, Washington."
AI's Output: Microsoft
Correct Output: Microsoft, Redmond, Washington
Score: 0.33
Task: Sentiment Analysis
Input Text: "The food was okay, but the service was exceptional."
AI's Output: Positive
Correct Output: Mixed
Score: 0
Task: Entity Extraction
Input Text: "Barack Obama was the 44th president of the United States."
AI's Output: Barack Obama
Correct Output: Barack Obama, United States
Score: 0.5"]
prompt = PromptTemplate.from_template(template)Ai evaluating Ai prompt template example.
List of LLM online metrics and details
https://gist.github.com/rupak-roy/c02dff34b6e3adf824ec41f563f487e1.js
Responsible Ai (RAI) metrics
Reference: Empowering Responsible AI Practices | Microsoft
RAI potential harm categories
https://gist.github.com/rupak-roy/b663125c99ba0b0e76a15722baa87cd9
Evaluation metrics by application scenarios
which we have seen some of them
https://gist.github.com/rupak-roy/c61a3dac6e5bc3388914f947e46e6150
LLM metrics for Q&A:
LLM metrics for Named Entity Recognition (NER):
LLM Benchmarks for text-to-SQL
Evaluation metrics for text-to-SQL tasks
Thanks for your time, i understand its a long article but i hope it helps. i tried to gather as much information as possible i can from across.
In the next article, we will explore Safeguarding LLMs Guardrails AI and NVIDIA’s NeMo Guardrails
Until then feel free to reach out. Thanks for your time, if you enjoyed this short article there are tons of topics in advanced analytics, data science, and machine learning available in my medium repo. https://medium.com/@bobrupakroy
Some of my alternative internet presences are Facebook, Instagram, Udemy, Blogger, Issuu, Slideshare, Scribd, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Let me know if you need anything. Talk Soon.



Comments
Post a Comment