Data Science Final Cook-Book Plug and Play Template
Data Science Final Cook-Book Plug and Play Template
Putting the whole data science journey in one template from data extraction to deployment in addition to updated MLOps practices like Model Decay. Worth reading it!

Hi everyone, today we will look into the steps that we can't miss to have in our pipeline from data extraction to model training and deployment.
This is a very useful cookbook that it took me some time to put all of the data science components together and it's worth reading it.
Let’s start at SQL database level.
- It starts with Feature Identification as are aware a SQL table can be more than 1000+ attributes, now our task is to export them batch-wise feature sample dataset (like 350 features at a time) and then merge them, a very tedious and time-consuming process. So the solution is to put a condition ‘ where table1.col1 <> not equal to NULL’ or <> not equal to 80% of them are null. Now you are left out with 600 features(as an example)
- Python version:
#Remove Na more than 70%
for i in df.columns:
print(i)
ratio = df[i].isna().sum()/df.shape[0]*100
print(ratio)
if ratio >=70:
print("yes")
print("ratio greater than 70% {}".format(i))
df.drop(i,axis=1,inplace=True)
print("{} dropped".format(i))
else:
passNext is
2. At Python Level: Eliminate features(categorial and numerical) with ‘near zero variance’ which means features have 90% most of the time the same value and will have(probability) 90% of the time the same value. Now we are left with 350 features(as an example)
Sample Code:
#drop columns that one unique value
df.drop(columns=df.columns[df.nunique()==1],inplace=True)Next is
3. Missing Value Treatment: we can use our regular mean, median, mode else some wrapper function. here is the same code that i wrote to automate the mean, median and mode.
Sample Code:
#function to check impute missing values
#1 checks for datatype
#2 if character impute mode
#3 if numberical check again skewness
#4 if skewed impute with median else mean
from scipy.stats import skew
def impute_missing(df,skewness_threshold =0.30):
for i in df.columns:
#temp = df.dtypes
if df[i].dtype =="object":
print("Character Variable Detected for ~", df[i].name)
print("Missing Value found",df[i].isna().sum())
df[i].fillna(df[i].mode()[0],inplace=True)
df[i] = df[i].astype("object")
print("Missing Values After imputation",df[i].isna().sum())
elif df[i].dtype == "int" or"float":
s_v = abs(skew(df[i]))
print("Numeric Variable Detected for ~", df[i].name)
if (s_v >=skewness_threshold or s_v <= skewness_threshold):
print("Missing Value found",df[i].isna().sum())
print("Skewness detected")
df[i].fillna(df[i].median(),inplace=True)
print("Missing Values After imputation",df[i].isna().sum())
else:
df[i].fillna(df[i].mean(skipna=True),inplace=True)
print("Missing Values After imputation",df[i].isna().sum())
else:
pass
return df
df1=impute_missing(df,0.30)Define X and y : independent and the dependent(target) variable, you can define this phase before the missing value treatment phase as some wrapper functions require X and y column name definitions.
Now apply
4. Multi-colinearity(numerical feat.): Perform Pearson’s correlation coefficient to remove attributes(Numeric) that have the same variance/ correlation. It's like having duplicate/ twin features, delete one and retain the other. Now we are left with 250 features(as an example)
(Optional) Attributes with feature correlation with the target using person correlation give an understanding of linear correlations with the target y.
Multi-colinearity for categorical features can be performed via the chi-square test. However, be careful of the assumptions
Sample Code:
#Multi colineartiy---------------------------
corr_matrix = X.corr().abs()
#select the upper triangle
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape),k=1).astype(np.bool))
#find features with correlation greater than 0.95
to_drop = [column for column in upper.columns if any(upper[column]>0.95)]
#drop the features
X.drop(to_drop,axis=1,inplace=True)5. Scaling: we need to apply to scale to bring all the attributes measurements/units into one scale i.e. mean of 0 and standard deviation = 1 applying the function from sklearn.preprocessing import standardscaler
sc = StandardScaler()
X_sc = pd.DataFrame(sc.fit_transform(df.select_dtypes(exclude= “object”)))
X _sc.columns= X.select_dtypes(exclude=’object’).columns
Also one of the other benefits of scaling is faster computation for next each phase of pipeline because the magnitude of data points now will be at the same scale.(example 350km=5.8, 4800USD amount = 10.7, 7 units = 1.94 etc. all be at the same scale)
6. Skewness transformation: We all know that the theorem of CLT Central Limit Theorem refers to the normal distribution in turn means the data is normally distribution, again when the data is normally distribution refers to the average behavior. But in real-life use cases/scenarios we won't be getting normally distribution gaussian data, so we will try to convert it to the approximate normal Gaussian distribution.
Another benefit of Skewness transformation is that when it shrinks the data with log, sqrt, cbrt etc. it automatically reduces the outliers. Thus helps in retaining valuable information.
Sample Code for Skewness transformation automation:
def skewness_correction(df,opt,skewness_threshold=0.5):
for i in df.columns:
if df[i].dtype =="int" or "float":
s_v = abs(skew(df[i]))
print("Skewness Value for {} is {} ####".format(df[i],s_v))
print("Skewness threshold",skewness_threshold)
if (s_v >=skewness_threshold or s_v <=skewness_threshold):
print("Skewness Before Correction", sns.displot(df[i]))
#print("Skew Value",s_v)
print("Skewness detected")
df[i] = opt(df[i]+1)
print("Skewness After Correction",sns.displot(df[i]))
print("Skewness Value after", skew(df[i]))
else:
pass
else:
pass
return df
X_sc = skewness_correction(X_sc,np.sqrt)
#Bring back the dataset in one piece object and numeric columns-------
#Prev 2 step we only use numberic dtype to process scaling and skewness
X = pd.concat([X_sc,X.select_dtypes(include='object')],axis=1) 7. Categorial Encoding: convert all the categorical attributes to pd.get_dummies(df,drop_first=True)
8. Feature Importance: Run a base model like a random forest to get the important features. Non-parametric model-based feature importance is highly preferable because they are not affected by any assumptions like in Hypothesis test anova, paired, t-test, Kendall rank coefficient, Somer-d, Wilcoxon signed ranked test etc. Now we will are left with 50 important features.
feat_imp = pd.Series(rf.feature_importances_,index=X.columns)
feat_imp.nlargest(30).sort_values().plot(kind='barh')Do consult with the SMEs about the features that got discarded at each iteration.
8.8 FEATURE ENGINEERING:
This is one of the important data science stages that should combine patterns to give more meaning and accuracy to the model.
Some of the already available wrappers are like polynomial feature engineering. here is the link on how to use it https://medium.com/@bobrupakroy/sklearn-polynomialfeatures-feature-engineering-8ec209af9f90
Featuretools, tsfresh, feature-engine and so on and so forth. i usually don't find auto feature engineering tools practical in nature as it takes a lot of time and is seriously computationally expensive.
9. Train Test Split and carry on with the machine learning model of your choice. The reason to perform train test split before is we will keep the test data purely untouched else test data will be effected by outlier treatment and smote treatment, again it depends on your strategy to evaluate the mode.
10. Outlier Treatment:
Sample Code
def remove_outliers(X_train,y_train):
from sklearn.ensemble import IsolationForest
iso = IsolationForest(contamination=0.1)
yhat = iso.fit_predict(X_train)
np.unique(yhat)
#select all teh rwos that are not outliers
mask = yhat != -1
X_train,y_train = X_train.values[mask,:],y_train.values[mask]
print("outlier removed")
return X_train,y_train
X_train,y_train = remove_outliers(X_train,y_train)1. Apply Class Imbalanced: I prefer SMOTETomek as the underlying documentation suggests better results when using both undersampling and oversampling.
Sample Code
def smote_function(X_train_res,y_train_res):
print("SMOTE Feature Active")
from imblearn.combine import SMOTETomek
smt = SMOTETomek(random_state=23)
X_train_res,y_train_res = smt.fit_resample(X_train,y_train)
print("Class balanced")
return X_train_res,y_train_res11. Train Test Split and carry on with the machine learning model of your choice.
MODEL EVALUATION — — — — — — — — — — —
12. Model Evaluation: we can build a dashboard using tools like streamlit to showcase the model performance using
12.1 Sklearn.metrics Classification Reports that include AUC, Precision, Recall, and Confusion Matrix etc.
12.2 Correction test. Test to find the probability that my FN, FP will be under alpha 0.05
Sample Code:
Holm Bonferroni correction
# Sort the p-values in ascending order
p_values_sorted = np.sort(p_values)
# These are the adjusted significance thresholds as an array.
# Each element is the threshold for the corresponding p-value in p_values_sorted
# Note that (np.arange(N_genes)+1)[::-1] gives an array with [N_genes, N_genes-1, N_genes-2, ..., 1]
# The [::-1] reverses the array.
holm_bonferroni_thresholds = 0.05/(np.arange(N_genes)+1)[::-1]
# First we compare the p-values to the associated thresholds. We then get an array
# where the p-values that exceed the threhold have a value of False.
holm_bonferroni_significant = p_values_sorted < holm_bonferroni_thresholds
# We want to find the first value of False in this array (first p-value that exceeds the threshold)
# so we invert it using logical_not.
holm_bonferroni_not_significant = np.logical_not(holm_bonferroni_significant)
# argwhere will return an array of indices for values of True in the supplied array.
# Taking the first element of this array gives the first value of True in holm_bonferroni_not_significant
# which is the same as the first value of False in holm_bonferroni_significant
holm_bonferroni_first_not_significant = np.argwhere(holm_bonferroni_not_significant)[0]
# We reject all hypothesis before the first p-value that exceeds the significance threshold.
# The number of these rejections is exactly equal to the index of the first value that
# exceeds the threshold.
num_holm_bonferroni_rejections = holm_bonferroni_first_not_significant
print(num_holm_bonferroni_rejections)
# Benjamini Hochberg
# These are the adjusted significance thresholds as an array.
benjamini_hochberg_thresholds = 0.05*(np.arange(N_genes)+1)/N_genes
# First we compare the p-values to the associated thresholds.
benjamini_hochberg_significant = p_values_sorted < benjamini_hochberg_thresholds
# We are intested in the last p-value which is significant.
# Remeber that argwhere returns an array of indicies for the True values, so
# we take the last element in order to get the index of the last p-value which
# is significant.
benjamini_hochberg_last_significant = np.argwhere(p_values_sorted < benjamini_hochberg_thresholds)[-1]
# We reject all hypotheses before the last significant p-value, AND we reject
# the hypothesis for the last significant p-value as well. So the number of rejected
# hypotheses is equal to the index of the last significant p-value PLUS one.
num_benjamini_hochberg_rejections = benjamini_hochberg_last_significant + 1
print(num_benjamini_hochberg_rejections)12.3 Model Inferences: further divided into #Model Specific if any and #Model Agnostic Methods like partial dependence plot, permutation feature important, shapley, auc-roc, plot,
SHap summary sample code
explainer = shap.TreeExplainer(loaded_model)
shap_values = explainer.shap_values(df)
explainer_class_val = np.unique(y)
print("Detail Attribute's Positive-Negative Impact/Influence Raw Table")
shap_class_val = pd.DataFrame(shap_values[explainer_class_val['class_label']])
shap_class_val.columns = df_shap.columns
print(shap_clas_val.describe(),style.highlight_max(color='blue',axis=1)
#kindly modify it accordingly 12.4 Advanced Model Analysis & Debugging: further divided into
#Memebership Inference: was the group data used for training?
Informational : * Membership Inference: was this data used for training. * Model Inversion: recreate the training data. *Model Extraction: recreate the model
Behavioral: *Poisoning: Insert malicious data into training data. *Evasion: input data that causes the model to intentionally misclassify the data.
# Poisosoning: detect the insertion of malicious data(anomaly) into training as well as scoring data.
Tools to measure the vulnerability of your model via
Cleverhans: an open source python library to benchmark machine learning system’s vulnerability to adversarial examples
Foolbox: an open-source python library that lets you easily run adversarial attacks against machine-learning models.
Defensive Distillation: advanced method. In other words, instead of transferring knowledge between different architectures, the authors proposed using knowledge distillation to improve a model’s own resilience to attacks.
12.5 Residual Analysis
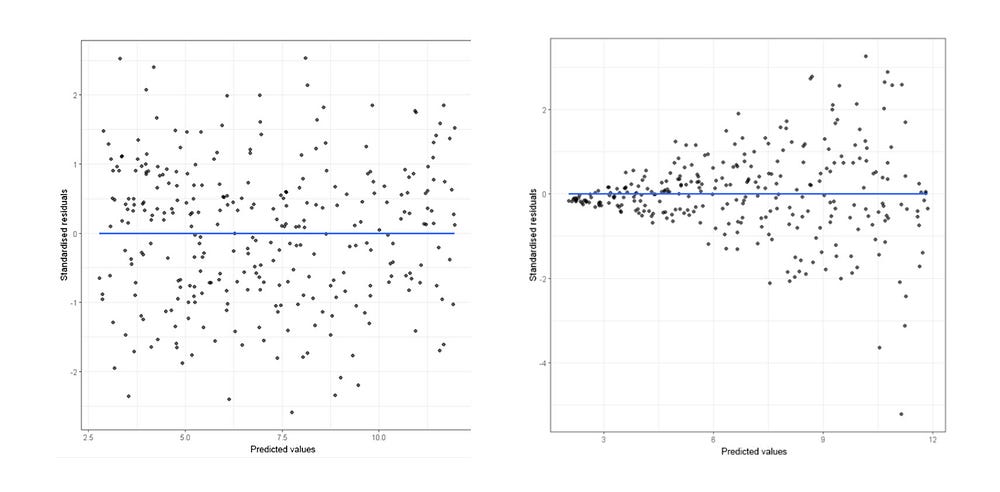
- Residual should not be correlated with another feature that was available but was left out of the feature vector. if you can predict the residuals with another feature that feature should be included int eh feature vector, This requires checking the unused features for correlation with residuals.
- Adjacent residuals shouldn’t be correlated with each other(autocorrelation). In other words, they should not be autocorrelated → if we can use residual to predict the next residual then there’s some predictive information that is not being captured by the model (Residual Plot).
- Dubin Watson test is also used for detecting autocorrelation.
12.6 Responsible Ai Interferences (high sensitivity data model)
Fairness — Ensure working towards systems that are fair and inclusive to all users. Explainlity helps ensure fairness.
Explainability — understanding how and why ML models make certain predictions. Explainability helps ensure fairness.
Privacy — training models require data that needs privacy-preserving safeguards for legal and regulatory concerns.
Security — Identifying potential threats can help keep Ai systems safe and secure.
Fairness-Check Function Definition
def fairness_metrics(df):
"""Calculate fairness for subgroup of population"""
#Confusion Matrix
cm=confusion_matrix(df['y'],df['y_pred'])
TN, FP, FN, TP = cm.ravel()
N = TP+FP+FN+TN #Total population
ACC = (TP+TN)/N #Accuracy
TPR = TP/(TP+FN) # True positive rate
FPR = FP/(FP+TN) # False positive rate
FNR = FN/(TP+FN) # False negative rate
PPP = (TP + FP)/N # % predicted as positive
return np.array([ACC, TPR, FPR, FNR, PPP])
#Calculate fairness metrics for race
fm_race_1 = fairness_metrics(df_fair[df_fair.priv_race==1])
fm_race_0 = fairness_metrics(df_fair[df_fair.priv_race==0])
#Get ratio of fairness metrics
fm_race = fm_race_0/fm_race_1Bias-Variance Decomposition: this will be you an intuition of how much the model is tilted to bias or variance.
from mlxtend.evaluate import bias_variance_decomp
tree = DecisionTreeClassifier(random_state=123)
avg_expected_loss, avg_bias, avg_var = bias_variance_decomp(
tree, X_train, y_train, X_test, y_test,
loss='0-1_loss',
random_seed=123)
print('Average expected loss: %.3f' % avg_expected_loss)
print('Average bias: %.3f' % avg_bias)
print('Average variance: %.3f' % avg_var)Business Fairness Check: This will contain the translation of model accuracy metrics into return on investment(ROI) metrics because the stakeholders, executives, and management won’t be interested in F1, Score, Precision, Recall Score, etc. Thus we need to show them the business profits like guaranteed sales of 5000 units every month for at least 6 months = 1.2 million pound profile.
12.7 Last and not least the model decay.
Causes of model decay — 1. Data Drift 2. Concept Drift
1. Data Drift(aka Feature Drift):
→ Statistical properties of input changes.
→ Trained model is not relevant for changed data.
→ For eg distribution of demographic data like age might change over time.
2. Concept Drift:
→ Relationship between features and labels changes. Eg. if your model is still predicting for T1 when the world is moved to T3 many of its predictions will be incorrect.
→ The way the meaning of what you’re trying to predict changes.
13. Logger
Try to add logs at every stage of the process is also one of the important MLOps practices. Logs as known it really helps to trace the error.
Sample Code
import logging
#create and configure logger
logging.basicConfig(filename=log_path+'log_'+project_name+'-'+current_now+'.csv',
format = '%(asctime)s - %(name)s - %(levelname)s-%(message)s',filemode='a',force=True)
#creating an object
logger_l = logging.getLogger()
#setting teh threshold of logger to Debug
logger_l.setLevel(logging.DEBUG)
#test messages
#logger_l.debug("Harmless Debug Message")
#logger_l.info("Just an information")
#logging_l.shutdown()
#Add this line to record
logger_l.info("1.Training-Script Data Pre-processing completed")
#to shutdown the log recording
logging_l.shutdown() Thats it! we don't with the training part.
Now we will look into the deployment side, it is almost the same with a few changes.
Deployment Steps Include:
- Data Extraction: Not Required as it will automatically read the files in the directory
- Feature Identification: NOT REQUIRED
- Missing Value Treatment: There is N number of strategies to treat the new missing values few of them i can think of fillna() with 0 which i personally prefer because 0 will have less influence over the model prediction. Second. Calculate the mean, median, and model for the new batch of data which will end up bias because every time the batch of new data will have different data distribution Even having a fixed value from the training phase like missing value treatment mean value =12 also for deployment phase sometimes i feel like biased. Third is during the training phase if you have a lot of missing values and any imputation will bias the dataset alternative solution is to treat the missing as a missing value category. Thus the model will not become biased.
- Multi-colinearity: NOT REQUIRED
- Scaling: REQUIRED. Load the scaling standard scaler model to apply the same scaling settings as was done during the training dataset.
- Skewness Transformation: REQUIRED. Use the same log transformation as was done during the model training dataset if applied np.log() transformation during the train phase and np. sqrt() during the deployment will be absolutely wrong.
- Categorical Encoding: REQUIRED. Do remember the number of categories during the training phase. If a categorical attribute like Country was encoded with 10 countries and later during the deployment we receive 15 countries' names it will crash your pipeline. For such scenarios try to include 1 extra category as “Others” so that no matter how many new categories will receive will be treated as “Others” and will continue with the prediction.
- Feature Importance: NOT REQUIRED.
- Train Test Split: Of course! NOT REQUIRED
- Outlier Treatment: Optional
- Class Imbalanced: NOT REQUIRED
- PERFORM MODEL PREDICTION
12.7 Model Decay: NOT REQUIRED. It's more about reporting of Model Prediction performance.
13. Logger: REQUIRED
That's it, done. I hope you enjoyed it and find this template useful.
Check out my previous article on MLOps Best Practices 2023
This article is a summary of my learning of MLOps Engineering in production from Courserabobrupakroy.medium.com
Bonus:
#better to Map rather than Encoders for the target as
#sometimes it might be sometimes confusioning during the inferences
#as we dont have control over the encoding
#example
height_dict = { 'very short':1, 'short':2
' normal':3, 'tall':4}
df["ordinal_height"] = df.height.map(height_dict)
#Alternatively
df["target"] = df["height"].replace(height_dict)
#Drop/Replace Nas/0 with np.nan in certrain columns to forward the data
#to be handled by missing value treatment process
#Example
df_temp = df.loc[:feature].replace(0,np.nan)
temp_ = df.loc[:,df_temp.columns.isin(features)]
df = pd.concat([df_temp,temp_],axis=1).reset_index(drop=True)
#Filter by value counts
#Very helpful when you have cardinal features/lot of categoies
dic = dict(df["offer_code"].value_counts() < =1000)
df["offer_code_count"] = df["offer_code"].map(dic)
df = df[df["offer_code_count"]==True].reset_index(drop=True)
#Difference two list
#example during deployment script we need to match the feature
#engineered feature list(which contains auto-reduce features) and
#reduce the new live data feature list
df_col_list = df2.columns.tolist()
diff_category_list = np.setdiff1d(df_col_list,numerical_feature_list)Thanks again, for your time, if you enjoyed this short article there are tons of topics in advanced analytics, data science, and machine learning available in my medium repo. https://medium.com/@bobrupakroy
Some of my alternative internet presences are Facebook, Instagram, Udemy, Blogger, Issuu, Slideshare, Scribd, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Let me know if you need anything. Talk Soon.



Comments
Post a Comment