Chained and MultiLabel Algorithms. New Guide to Advanced Predictive analytics via Multi-label, Multi-output & Chained
Hi everyone, how are you doing? great! Likewise long story short, today we will look into some advanced techniques of machine learning commonly named as Multi-Class and Multi-Label.
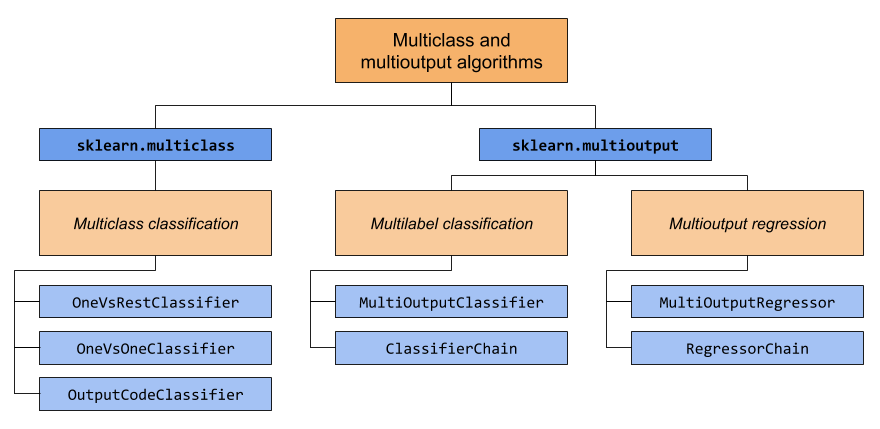
To make it clear I have put the diagram from scikit
From the above diagram, we can clearly see how they are split into.
1. Multiclass — This we are already aware of and most of the sklearn classifiers support the multiclass by default. Here is the list below just in case:
Next, we have 2. MultiLabel Classification, we call it MultiLabel Classification because we will be performing classification tasks and for regression, we called it as 3. Multioutput Regression.
2. MultiLabel Classification is further divided into
— MultiOutput Classifier
— Classifier Chain
— MultiLabel MultiOutput Classifier #This strategy consists of fitting one classifier per target. #his is a simple strategy for extending classifiers that do not natively support multi-target classification.
import numpy as np
from sklearn.datasets import make_multilabel_classification
from sklearn.multioutput import MultiOutputClassifier
from sklearn.linear_model import LogisticRegression
#create dataset
X, y = make_multilabel_classification(n_classes=3, random_state=0)
clf = MultiOutputClassifier(LogisticRegression()).fit(X, y)
clf.predict(X[-2:])
— MultiLabel Classifier Chain
#Classifier chains are a way of combining a number of #binary classifiers into a single multi-label model that is capable of exploiting correlations among targets. “Each model makes a prediction in the order specified by the chain using all of the available features provided to the model plus the predictions of models that are earlier in the chain.’’
In simple words,
For example, classification of the properties “type of fruit” and “color” for a set of images of fruit. The property “type of fruit” has the possible classes: “apple”, “pear” and “orange”. The property “color” has the possible classes: “green”, “red”, “yellow” and “orange”. Each sample is an image of a fruit, a label is output for both properties and each label is one of the possible classes of the corresponding property.
from sklearn.datasets import make_multilabel_classification
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.multioutput import ClassifierChain
#make dataset
X, Y = make_multilabel_classification(n_samples=12, n_classes=3, random_state=0)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0)
base_lr = LogisticRegression(solver='lbfgs', random_state=0)
chain = ClassifierChain(base_lr, order='random', random_state=0)
chain.fit(X_train, Y_train).predict(X_test)
chain.predict_proba(X_test)
3. MultiOutput Regression similarly into
— Multioutput Regressor
— Regressor Chain
In multioutput regression, involves dividing the regression problem into a separate problem for each target variable to be predicted.
#The Approach assumes that the outputs are independent of each other, In other words, the approach involves developing a separate regression model for each output value to be predicted.
For example, if a multioutput regression problem required the prediction of three values y1, y2 and y3 given an input X, then this could be partitioned into three single-output regression problems: Problem 1: Given X, predict y1. Problem 2: Given X, predict y2. Problem 3: Given X, predict y3.
Some regression machine learning algorithms support multiple outputs directly. #LinearRegression (and related) #KNeighborsRegressor #DecisionTreeRegressor #RandomForestRegressor (and related)
Multi-step time series forecasting may be considered a type of multiple-output regression where a sequence of future values are predicted and each predicted value is dependent upon the prior values in the sequence.
#1 linear regression for multioutput regression-----------------
from sklearn.datasets import make_regression
from sklearn.linear_model import LinearRegression
# create datasets
X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, n_targets=2, random_state=1, noise=0.5)
# define model
model = LinearRegression()
# fit model
model.fit(X, y)
# make a prediction
row = [0.21947749, 0.32948997, 0.81560036, 0.440956, -0.0606303, -0.29257894, -0.2820059, -0.00290545, 0.96402263, 0.04992249]
yhat = model.predict([row])
# summarize prediction
print(yhat[0])
#2 k-nearest neighbors for multioutput regression------------------
from sklearn.datasets import make_regression
from sklearn.neighbors import KNeighborsRegressor
# create datasets
X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, n_targets=2, random_state=1, noise=0.5)
# define model
model = KNeighborsRegressor()
# fit model
model.fit(X, y)
# make a prediction
row = [0.21947749, 0.32948997, 0.81560036, 0.440956, -0.0606303, -0.29257894, -0.2820059, -0.00290545, 0.96402263, 0.04992249]
yhat = model.predict([row])
# summarize prediction
print(yhat[0])
#3 decision tree for multioutput regression----------------
from sklearn.datasets import make_regression
from sklearn.tree import DecisionTreeRegressor
# create datasets
X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, n_targets=2, random_state=1, noise=0.5)
# define model
model = DecisionTreeRegressor()
# fit model
model.fit(X, y)
# make a prediction
row = [0.21947749, 0.32948997, 0.81560036, 0.440956, -0.0606303, -0.29257894, -0.2820059, -0.00290545, 0.96402263, 0.04992249]
yhat = model.predict([row])
# summarize prediction
print(yhat[0])
— Multioutput sklearn-Wrapper Approach
for using those models that don't support by default
from sklearn.datasets import make_regression
from sklearn.multioutput import MultiOutputRegressor
from sklearn.svm import LinearSVR
# define dataset
X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, n_targets=2, random_state=1, noise=0.5)
# define base model
model = LinearSVR()
#define the multioutput wrapper model
wrapper = MultiOutputRegressor(model)
# fit the model
wrapper.fit(X, y)
# make a single prediction
row = [0.21947749, 0.32948997, 0.81560036, 0.440956, -0.0606303, -0.29257894, -0.2820059, -0.00290545, 0.96402263, 0.04992249]
yhat = wrapper.predict([row])
# summarize the prediction
print('Predicted: %s' % yhat[0])
— Regressor Chain
Regressor Chain develops a sequence of dependent models to match the number of numerical values to be predicted.
The approach is an extension of the multioutput method except the models are organized into a chain. The prediction from the first model is taken as part of the input to the second model, and the process of output-to-input dependency repeats along the chain of models.
For example, if a problem required the prediction of three values y1, y2 and y3 given an input X, then this could be partitioned into three dependent single-output regression problems as follows: Problem 1(yhat1): Given X, predict y1. Problem 2(yhat2): Given X and yhat1, predict y2. Problem 3: Given X, yhat1, and yhat2, predict y3.
from numpy import mean
from numpy import std
from numpy import absolute
from sklearn.datasets import make_regression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedKFold
from sklearn.multioutput import RegressorChain
from sklearn.svm import LinearSVR
# define dataset
X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, n_targets=2, random_state=1, noise=0.5)
# define base model
model = LinearSVR()
# define the chain model
wrapper = RegressorChain(model)
# define the evaluation procedure
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
# evaluate the model and collect the scores
n_scores = cross_val_score(wrapper, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1)
# force the scores to be positive
n_scores = absolute(n_scores)
# summarize performance
print('MAE: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
Here we go, We have our commonly used methods/ways to perform multilabel classification as well regression modeling techniques.
There are a couple few more techniques to perform multiclass like OutputCode, Binary Relevance, Adapted Algorithm, and Ensemble Approaches, MultiLabel for Deep Learning which we will look at in the next article, Stay Tune!
Likewise, long story short I tried to bring to the best of from across and rephrasing it into a more simplified version, i will try to bring as much as possible new content across the data science realm and i hope the package will be useful at some point in your work. Because I believe machine learning is not replacing us, it’s about replacing the same iterative work that consumes time and much effort. So people should come to work to create innovations rather than be occupied in the same repetitive boring tasks.
Thanks again, for your time, if you enjoyed this short article there are tons of topics in advanced analytics, data science, and machine learning available in my medium repo. https://medium.com/@bobrupakroy
Some of my alternative internet presencesFacebook, Instagram, Udemy, Blogger, Issuu, Slideshare, Scribd and more.




Comments
Post a Comment