Data Science Interview Q’s — V A walkthrough with/from the essentials of data science interviews.
Data Science Interview Q’s — V
A walkthrough with/from the essentials of data science interviews.

Hi hey there, thanks for the continuous support for my previous articles. Today we will continue from our previous article “Data Science Interview Q’s — IV” PART-IV, the commonly asked essential questions by the interviewers to understand the root level knowledge of DS rather than going for fancy advanced questions.
1. Is the decision boundary linear or nonlinear in the case of a logistic regression model?
The decision boundary is a line that separates the target variables into different classes. The decision boundary can either be linear or nonlinear. In case of a logistic regression model, the decision boundary is a straight line.
Logistic regression model formula = α+1X1+2X2+….+kXk. This clearly represents a straight line. Logistic regression is only suitable in such cases where a straight line is able to separate the different classes. If a straight line is not able to do it, then nonlinear algorithms should be used to achieve better results.
2. What is the likelihood function?
The likelihood function is the joint probability of observing the data. For example, let’s assume that a coin is tossed 100 times and we want to know the probability of getting 60 heads from the tosses. This example follows the binomial distribution formula.
p = Probability of heads from a single coin toss
n = 100 (the number of coin tosses)
x = 60 (the number of heads — success)
n-x = 30 (the number of tails)
Pr(X=60 |n = 100, p)
The likelihood function is the probability that the number of heads received is 60 in a trail of 100 coin tosses, where the probability of heads received in each coin toss is p. Here the coin toss result follows a binomial distribution.
This can be reframed as follows:
Pr(X=60|n=100,p) = c x p60x(1-p)100–60
c = constant
p = unknown parameter
The likelihood function gives the probability of observing the results using unknown parameters.
3. What is the Maximum Likelihood Estimator (MLE)?
The MLE chooses those sets of unknown parameters (estimator) that maximise the likelihood function. The method to find the MLE is to use calculus and setting the derivative of the logistic function with respect to an unknown parameter to zero, and solving it will give the MLE. For a binomial model, this will be easy, but for a logistic model, the calculations are complex. Computer programs are used for deriving MLE for logistic models.
(Here’s another approach to answering the question.)
MLE is a statistical approach to estimating the parameters of a mathematical model. MLE and ordinary square estimation give the same results for linear regression if the dependent variable is assumed to be normally distributed. MLE does not assume anything about independent variables.
4. What are the different methods of MLE and when is each method preferred?
In case of logistics regression, there are two approaches of MLE. They are conditional and unconditional methods. Conditional and unconditional methods are algorithms that use different likelihood functions. The unconditional formula employs joint probability of positives (for example, churn) and negatives (for example, non-churn). The conditional formula is the ratio of the probability of observed data to the probability of all possible configurations.
The unconditional method is preferred if the number of parameters is lower compared to the number of instances. If the number of parameters is high compared to the number of instances, then conditional MLE is to be preferred. Statisticians suggest that conditional MLE is to be used when in doubt. Conditional MLE will always provide unbiased results.
5. What are the advantages and disadvantages of conditional and unconditional methods of MLE?
Conditional methods do not estimate unwanted parameters. Unconditional methods estimate the values of unwanted parameters also. Unconditional formulas can directly be developed with joint probabilities. This cannot be done with conditional probability. If the number of parameters is high relative to the number of instances, then the unconditional method will give biased results. Conditional results will be unbiased in such cases.
6. What is the output of a standard MLE program?
The output of a standard MLE program is as follows:
Maximised likelihood value: This is the numerical value obtained by replacing the unknown parameter values in the likelihood function with the MLE parameter estimator.
Estimated variance-covariance matrix: The diagonal of this matrix consists of estimated variances of the ML estimates. The off-diagonal consists of the covariances of the pairs of the ML estimates.
7. Why can’t we use Mean Square Error (MSE) as a cost function for logistic regression?
In logistic regression, we use the sigmoid function and perform a non-linear transformation to obtain the probabilities. Squaring this non-linear transformation will lead to non-convexity with local minimums. Finding the global minimum in such cases using gradient descent is not possible. Due to this reason, MSE is not suitable for logistic regression. Cross-entropy or log loss is used as a cost function for logistic regression. In the cost function for logistic regression, the confident wrong predictions are penalised heavily. The confident right predictions are rewarded less. By optimising this cost function, convergence is achieved.
8. Why is accuracy not a good measure for classification problems?
Accuracy is not a good measure for classification problems because it gives equal importance to both false positives and false negatives. However, this may not be the case in most business problems. For example, in case of cancer prediction, declaring cancer as benign is more serious than wrongly informing the patient that he is suffering from cancer. Accuracy gives equal importance to both cases and cannot differentiate between them.
9. What are the true positive rate (TPR), true negative rate (TNR), false-positive rate (FPR), and false-negative rate (FNR)?
TPR refers to the ratio of positives correctly predicted from all the true labels. In simple words, it is the frequency of correctly predicted true labels.
TPR = TP/TP+FN
TNR refers to the ratio of negatives correctly predicted from all the false labels. It is the frequency of correctly predicted false labels.
TNR = TN/TN+FP
FPR refers to the ratio of positives incorrectly predicted from all the true labels. It is the frequency of incorrectly predicted false labels.
FPR = FP/TN+FP
FNR refers to the ratio of negatives incorrectly predicted from all the false labels. It is the frequency of incorrectly predicted true labels.
FNR = FN/TP+FN
10. What are precision and recall?
Precision is the proportion of true positives out of predicted positives. To put it in another way, it is the accuracy of the prediction. It is also known as the ‘positive predictive value’.
Precision = TP/TP+FP
Recall is same as the true positive rate (TPR).
11. What is F-measure?
It is the harmonic mean of precision and recall. In some cases, there will be a trade-off between the precision and the recall. In such cases, the F-measure will drop. It will be high when both the precision and the recall are high. Depending on the business case at hand and the goal of data analytics, an appropriate metric should be selected.
F-measure = 2 X (Precision X Recall) / (Precision+Recall)
12. What are sensitivity and specificity?
Specificity is the same as true negative rate, or it is equal to 1 — false-positive rate.
Specificity = TN/TN + FP.
Sensitivity is the true positive rate.
Sensitivity = TP/TP + FN
13. What is a cumulative response curve (CRV)?
In order to convey the results of an analysis to the management, a ‘cumulative response curve’ is used, which is more intuitive than the ROC curve. A ROC curve is very difficult to understand for someone outside the field of data science. A CRV consists of the true positive rate or the percentage of positives correctly classified on the Y-axis and the percentage of the population targeted on the X-axis. It is important to note that the percentage of the population will be ranked by the model in descending order (either the probabilities or the expected values). If the model is good, then by targeting a top portion of the ranked list, all high percentages of positives will be captured. As with the ROC curve, there will be a diagonal line which represents random performance. Let’s understand this random performance as an example. Assuming that 50% of the list is targeted, it is expected that it will capture 50% of the positives. This expectation is captured by the diagonal line, which is similar to the ROC curve.
9. What are the lift curves?
The lift is the improvement in model performance (increase in true positive rate) when compared to random performance. Random performance means if 50% of the instances is targeted, then it is expected that it will detect 50% of the positives. Lift is in comparison to the random performance of a model. If a model’s performance is better than its random performance, then its lift will be greater than 1.
In a lift curve, lift is plotted on the Y-axis and the percentage of the population (sorted in descending order) on the X-axis. At a given percentage of the target population, a model with a high lift is preferred.
10. Which algorithm is better at handling outliers logistic regression or SVM?
Logistic regression will find a linear boundary if it exists to accommodate the outliers. Logistic regression will shift the linear boundary in order to accommodate the outliers. SVM is insensitive to individual samples. There will not be a major shift in the linear boundary to accommodate an outlier. SVM comes with inbuilt complexity controls, which take care of overfitting. This is not true in case of logistic regression.
11. How will you deal with the multiclass classification problem using logistic regression?
The most famous method of dealing with multiclass classification using logistic regression is using the one-vs-all approach. Under this approach, a number of models are trained, which is equal to the number of classes. The models work in a specific way. For example, the first model classifies the datapoint depending on whether it belongs to class 1 or some other class; the second model classifies the datapoint into class 2 or some other class. This way, each data point can be checked over all the classes.
12. Explain the use of ROC curves and the AUC of an ROC Curve.
An ROC (Receiver Operating Characteristic) curve illustrates the performance of a binary classification model. It is basically a TPR versus FPR (true positive rate versus false-positive rate) curve for all the threshold values ranging from 0 to 1. In a ROC curve, each point in the ROC space will be associated with a different confusion matrix. A diagonal line from the bottom-left to the top-right on the ROC graph represents random guessing. The Area Under the Curve (AUC) signifies how good the classifier model is. If the value for AUC is high (near 1), then the model is working satisfactorily, whereas if the value is low (around 0.5), then the model is not working properly and just guessing randomly.
13. How can you use the concept of ROC in a multiclass classification?
The concept of ROC curves can easily be used for multiclass classification by using the one-vs-all approach. For example, let’s say that we have three classes ‘a’, ’b’, and ‘c’. Then, the first class comprises class ‘a’ (true class) and the second class comprises both class ‘b’ and class ‘c’ together (false class). Thus, the ROC curve is plotted. Similarly, for all the three classes, we will plot three ROC curves and perform our analysis of AUC.
14. What is the use of regularisation? Explain L1 and L2 regularisations.
Regularisation is a technique that is used to tackle the problem of overfitting of the model. When a very complex model is implemented on the training data, it overfits. At times, the simple model might not be able to generalise the data and the complex model overfits. To address this problem, regularisation is used.
Regularisation is nothing but adding the coefficient terms (betas) to the cost function so that the terms are penalised and are small in magnitude. This essentially helps in capturing the trends in the data and at the same time prevents overfitting by not letting the model become too complex.
· L1 or LASSO regularisation: Here, the absolute values of the coefficients are added to the cost function. This can be seen in the following equation; the highlighted part corresponds to the L1 or LASSO regularisation. This regularisation technique gives sparse results, which lead to feature selection as well.
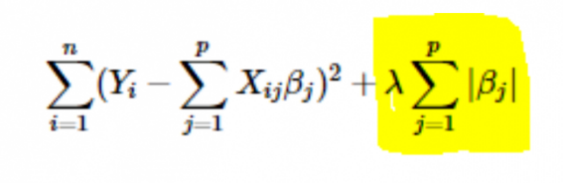
· L2 or Ridge regularisation: Here, the squares of the coefficients are added to the cost function. This can be seen in the following equation, where the highlighted part corresponds to the L2 or Ridge regularisation.
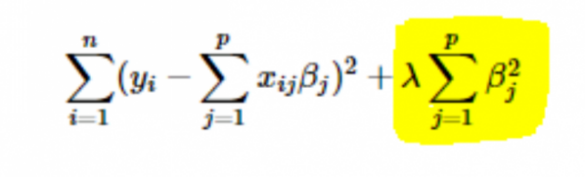
15. How to choose the value of the regularisation parameter (λ)?
Selecting the regularisation parameter is a tricky business. If the value of λ is too high, it will lead to extremely small values of the regression coefficient β, which will lead to the model underfitting (high bias — low variance). On the other hand, if the value of λ is 0 (very small), the model will tend to overfit the training data (low bias — high variance).
There is no proper way to select the value of λ. What you can do is have a sub-sample of data and run the algorithm multiple times on different sets. Here, the person has to decide how much variance can be tolerated. Once the user is satisfied with the variance, that value of λ can be chosen for the full dataset.
One thing to be noted is that the value of λ selected here was optimal for that subset, not for the entire training data.
16. Can we use linear regression for time series analysis?
One can use linear regression for time series analysis, but the results are not promising. So, it is generally not advisable to do so. The reasons behind this are —
1. Time series data is mostly used for the prediction of the future, but linear regression seldom gives good results for future prediction as it is not meant for extrapolation.
2. Mostly, time series data have a pattern, such as during peak hours, festive seasons, etc., which would most likely be treated as outliers in the linear regression analysis.
17. What value is the sum of the residuals of a linear regression close to? Justify.
The sum of the residuals of a linear regression is 0. Linear regression works on the assumption that the errors (residuals) are normally distributed with a mean of 0,
18. You run your regression on different subsets of your data, and in each subset, the beta value for a certain variable varies wildly. What could be the issue here?
This case implies that the dataset is heterogeneous. So, to overcome this problem, the dataset should be clustered into different subsets, and then separate models should be built for each cluster. Another way to deal with this problem is to use non-parametric models, such as decision trees, which can deal with heterogeneous data quite efficiently.
19. Your linear regression doesn’t run and communicates that there is an infinite number of best estimates for the regression coefficients. What could be wrong?
This condition arises when there is a perfect correlation (positive or negative) between some variables. In this case, there is no unique value for the coefficients, and hence, the given condition arises.
20. What do you mean by adjusted R2? How is it different from R2?
Adjusted R2, just like R2, is a representative of the number of points lying around the regression line. That is, it shows how well the model is fitting the training data.
One drawback of R2 is that it will always increase with the addition of a new feature, whether the new feature is useful or not. The adjusted R2 overcomes this drawback. The value of the adjusted R2 increases only if the newly added feature plays a significant role in the model
21. How do you interpret the residual vs fitted value curve?
The residual vs fitted value plot is used to see whether the predicted values and residuals have a correlation or not. If the residuals are distributed normally, with a mean around the fitted value and a constant variance, our model is working fine; otherwise, there is some issue with the model.
The most common problem that can be found when training the model over a large range of a dataset is heteroscedasticity(this is explained in the answer below). The presence of heteroscedasticity can be easily seen by plotting the residual vs fitted value curve.
22. What is heteroscedasticity? What are the consequences, and how can you overcome it?
A random variable is said to be heteroscedastic when different subpopulations have different variabilities (standard deviation).
The existence of heteroscedasticity gives rise to certain problems in the regression analysis as the assumption says that error terms are uncorrelated and, hence, the variance is constant. The presence of heteroscedasticity can often be seen in the form of a cone-like scatter plot for residual vs fitted values.
One of the basic assumptions of linear regression is that heteroscedasticity is not present in the data. Due to the violation of assumptions, the Ordinary Least Squares (OLS) estimators are not the Best Linear Unbiased Estimators (BLUE). Hence, they do not give the least variance than other Linear Unbiased Estimators (LUEs).
There is no fixed procedure to overcome heteroscedasticity. However, there are some ways that may lead to a reduction of heteroscedasticity. They are —
1. Logarithmising the data: A series that is increasing exponentially often results in increased variability. This can be overcome using the log transformation.
2. Using weighted linear regression: Here, the OLS method is applied to the weighted values of X and Y. One way is to attach weights directly related to the magnitude of the dependent variable.
23. How is hypothesis testing used in linear regression?
Hypothesis testing can be carried out in linear regression for the following purposes:
1. To check whether a predictor is significant for the prediction of the target variable. Two common methods for this are —
2. By the use of p-values:
If the p-value of a variable is greater than a certain limit (usually 0.05), the variable is insignificant in the prediction of the target variable.
3. By checking the values of the regression coefficient:
If the value of regression coefficient corresponding to a predictor is zero, that variable is insignificant in the prediction of the target variable and has no linear relationship with it.
4. To check whether the calculated regression coefficients are good estimators of the actual coefficients.
24. Which graphs are suggested to be observed before model fitting?
Before fitting the model, one must be well aware of the data, such as what the trends, distribution, skewness, etc. in the variables are. Graphs such as histograms, box plots, and dot plots can be used to observe the distribution of the variables. Apart from this, one must also analyse what the relationship between dependent and independent variables is. This can be done by scatter plots (in case of univariate problems), rotating plots, dynamic plots, etc.
25. What is the generalized linear model?
The generalized linear model is the derivative of the ordinary linear regression model. GLM is more flexible in terms of residuals and can be used where linear regression does not seem appropriate. GLM allows the distribution of residuals to be other than a normal distribution. It generalizes the linear regression by allowing the linear model to link to the target variable using the linking function. Model estimation is done using the method of maximum likelihood estimation.
26. You will see two statements listed below. You will have to read both of them carefully and then choose one of the options from the two statements’ options. The contextual question is, Choose the statements which are true about bagging trees.
1. The individual trees are not at all dependent on each other for a bagging tree.
2. To improve the overall performance of the model, the aggregate is taken from weak learners. This method is known as bagging trees.
3. Only statement number one is TRUE.
4. Only statement number two is TRUE.
5. Both statements one and two are TRUE.
6. None of the options which are mentioned above.
Ans. The correct answer to this question is C because, for a bagging tree, both of these statements are true. In bagging trees or bootstrap aggregation, the main goal of applying this algorithm is to reduce the amount of variance present in the decision tree. The mechanism of creating a bagging tree is that with replacement, a number of subsets are taken from the sample present for training the data.
Now, each of these smaller subsets of data is used to train a separate decision tree. Since the information which is fed into each tree comes out to be unique, the likelihood of any tree having any impact on the other becomes very low. The final result which all these trees give is collected and then processed to provide the output. Thus, the second statement also comes out to be true.
27. You will see two statements listed below. You will have to read both of them carefully and then choose one of the options from the two statements’ options. The contextual question is, Choose the statements which are true about boosting trees.
1. The weak learners in a boosting tree are independent of each other.
2. The weak learners’ performance is all collected and aggregated to improve the boosted tree’s overall performance.
3. Only statement number one is TRUE.
4. Only statement number two is TRUE.
5. Both statements one and two are TRUE.
6. None of the options which are mentioned above.
Ans. If you were to understand how the boosting of trees is done, you will understand and will be able to differentiate the correct statement from the statement, which is false. So, a boosted tree is created when many weak learners are connected in series. Each tree present in this sequence has one sole aim: to reduce the error which its predecessor made.
If the trees are connected in such fashion, all the trees cannot be independent of each other, thus rendering the first statement false. When coming to the second statement, it is true mainly because, in a boosted tree, that is the method that is applied to improve the overall performance of the model. The correct option will be B, i.e., only the statement number two is TRUE, and the statement number one is FALSE.
28. You will see four statements listed below. You will have to read all of them carefully and then choose one of the options from the options which follows the four statements. The contextual question is, Choose the statements which are true about Radom forests and Gradient boosting ensemble method.
1. Both Random forest and Gradient boosting ensemble methods can be used to perform classification.
2. Random Forests can be used to perform classification tasks, whereas the gradient boosting method can only perform regression.
3. Gradient boosting can be used to perform classification tasks, whereas the Random Forest method can only perform regression.
4. Both Random forest and Gradient boosting ensemble methods can be used to perform regression.
5. Only statement number one is TRUE.
6. Only statement number two is TRUE.
7. Both statements one and two are TRUE.
8. Only statement number three is TRUE
9. Only statement number four is TRUE
10. Only statement number one and four is TRUE
Ans. The answer to this question is straightforward. Both of these ensemble methods are actually very capable of doing both classification and regression tasks. So, the answer to this question would be F because only statements number one and four are TRUE.
29. You will see four statements listed below. You will have to read all of them carefully and then choose one of the options from the options which follows the four statements. The contextual question is, consider a random forest of trees. So what will be true about each or any of the trees in the random forest?
1. Each tree that constitutes the random forest is based on the subset of all the features.
2. Each of the in a random forest is built on all the features.
3. Each of the trees in a random forest is built on a subset of all the observations present.
4. Each of the trees in a random forest is built on the full observation set.
5. Only statement number one is TRUE.
6. Only statement number two is TRUE.
7. Both statements one and two are TRUE.
8. Only statement number three is TRUE
9. Only statement number four is TRUE
10. Both statements number one and four are TRUE
11. Both the statements number one and three are TRUE
12. Both the statements number two and three are TRUE
13. Both the statements number two and four are TRUE
Ans. The generation of random forests is based on the concept of bagging. To build a random forest, a small subset is taken from both the observations and the features. The values which are obtained after taking out the subsets are then fed into singular decision trees. Then all the values from all such decision trees are collected to make the final decision. That means the only statements which are correct would be one and three. So, the right option would be G.
30. You will see four statements listed below. You will have to read all of them carefully and then choose one of the options from the options which follows the four statements. The contextual question is, select the correct statements about the hyperparameter known as “max_depth” of the gradient boosting algorithm.
1. Choosing a lower value of this hyperparameter is better if the validation set’s accuracy is similar.
2. Choosing a higher value of this hyperparameter is better if the validation set’s accuracy is similar.
3. If we are to increase this hyperparameter’s value, then the chances of this model actually overfitting the data increases.
4. If we are to increase this hyperparameter’s value, then the chances of this model actually underfitting the data increases.
5. Only statement number one is TRUE.
6. Only statement number two is TRUE.
7. Both statements one and two are TRUE.
8. Only statement number three is TRUE
9. Only statement number four is TRUE
10. Both statements number one and four are TRUE
11. Both the statements number one and three are TRUE
12. Both the statements number two and three are TRUE
13. Both the statements number two and four are TRUE
14.
Ans. The hyperparameter max_depth controls the depth until the gradient boosting will model the presented data in front of it. If you keep on increasing the value of this hyperparameter, then the model is bound to overfit. So, statement number three is correct. If we have the same scores on the validation data, we generally prefer the model with a lower depth. So, statements number one and three are correct, and thus the answer to this decision tree interview questions is g.
31. You will see four statements listed below. You will have to read all of them carefully and then choose one of the options from the options which follows the four statements. The contextual question is which of the following methods does not have a learning rate as one of their tunable hyperparameters.
1. Extra Trees.
2. AdaBoost
3. Random Forest
4. Gradient boosting.
5. Only statement number one is TRUE.
6. Only statement number two is TRUE.
7. Both statements one and two are TRUE.
8. Only statement number three is TRUE
9. Only statement number four is TRUE
10. Both statements number one and four are TRUE
11. Both the statements number one and three are TRUE
12. Both the statements number two and three are TRUE
13. Both the statements number two and four are TRUE
Ans. Only Extra Trees and Random forest does not have a learning rate as one of their tunable hyperparameters. So, the answer would be g because the statement number one and three are TRUE.
32. Choose the option, which is true.
1. Only in the algorithm of random forest, real values can be handled by making them discrete.
2. Only in the algorithm of gradient boosting, real values can be handled by making them discrete.
3. In both random forest and gradient boosting, real values can be handled by making them discrete.
4. None of the options which are mentioned above.
Ans. Both of the algorithms are capable ones. They both can easily handle the features which have real values in them. So, the answer to this decision tree interview questions and answers is C.
33. Choose one option from the list below. The question is, choose the algorithm which is not an ensemble learning algorithm.
1. Gradient boosting
2. AdaBoost
3. Extra Trees
4. Random Forest
5. Decision Trees
Ans. This question is straightforward. Only one of these algorithms is not an ensemble learning algorithm. One thumb rule to keep in mind will be that any ensemble learning method would involve the use of more than one decision tree. Since in option E, there is just the singular decision tree, then that is not an ensemble learning algorithm. So, the answer to this question would be E (decision trees).
34. You will see two statements listed below. You will have to read both of them carefully and then choose one of the options from the two statements’ options. The contextual question is, which of the following would be true in the paradigm of ensemble learning.
1. The tree count in the ensemble should be as high as possible.
2. You will still be able to interpret what is happening even after you implement the algorithm of Random Forest.
3. Only statement number one is TRUE.
4. Only statement number two is TRUE.
5. Both statements one and two are TRUE.
6. None of the options which are mentioned above.
Ans. Since any ensemble learning method is based on coupling a colossal number of decision trees (which on its own is a very weak learner) together so it will always be beneficial to have more number of trees to make your ensemble method. However, the algorithm of random forest is like a black box. You will not know what is happening inside the model. So, you are bound to lose all the interpretability after you apply the random forest algorithm. So, the correct answer to this question would be A because only the statement that is true is statement number one.
35. Answer in only in TRUE or FALSE. Algorithm of bagging works best for the models which have high variance and low bias?
Ans. True. Bagging indeed is most favorable to be used for high variance and low bias model.
36 . You will see two statements listed below. You will have to read both of them carefully and then choose one of the options from the two statements’ options. The contextual question is, choose the right ideas for Gradient boosting trees.
1. In every stage of boosting, the algorithm introduces another tree to ensure all the current model issues are compensated.
2. We can apply a gradient descent algorithm to minimize the loss function.
3. Only statement number one is TRUE.
4. Only statement number two is TRUE.
5. Both statements one and two are TRUE.
6. None of the options which are mentioned above.
Ans. The answer to this question is C meaning both of the two options are TRUE. For the first statement, that is how the boosting algorithm works. The new trees introduced into the model are just to augment the existing algorithm’s performance. Yes, the gradient descent algorithm is the function that is applied to reduce the loss function.
37. In the gradient boosting algorithm, which of the statements below are correct about the learning rate?
1. The learning rate which you set should be as high as possible.
2. The learning rate which you set should not be as high as possible rather as low as you can make it.
3. The learning rate should be low but not very low.
4. The learning rate which you are setting should be high but not super high.
Ans. The learning rate should be low, but not very low, so the answer to this decision tree interview questions and answers would be option C.
I hope you will find the questionnaires useful for your career and also the credit goes to up grad from i was able to gather this set of interview questionnaires for you.
Next, we will walk through the more advanced topics of data science like comparing the 2 machine learning models.

Thanks again, for your time, if you enjoyed this short article there are tons of topics in advanced analytics, data science, and machine learning available in my medium repo. https://medium.com/@bobrupakroy
Some of my alternative internet presences Facebook, Instagram, Udemy, Blogger, Issuu, Slideshare, Scribd and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Let me know if you need anything. Talk Soon.


Comments
Post a Comment