Multivariate MultiStep LSTM
Multivariate MultiStep LSTM
Powerful Approach Forecasting beyond dataset

Hi, how things are up to? good great better? i hope its all good.
Today i will demonstrate you how to perform multi-variate and multistep forecasting, which means forecasting beyond the dataset.
We have seen tons of examples, all are claiming multivariate and not multistep, similarly multistep but multivariate LSTM, very difficult to get a proper example.
So i took the initiative to write a proper example that can be used as a template.
If you wish to understand more about LSTM how it works? tons of articles available on google or you can simply follow my previous articles' very in-detail workflow of LSTM, Follow the link below
Apply State Of The Art Deep Learning Time Series Forecasting with the help of this template.bobrupakroy.medium.com
The intuition behind Multi-Variate Multi-Step LSTM output is as shown below.
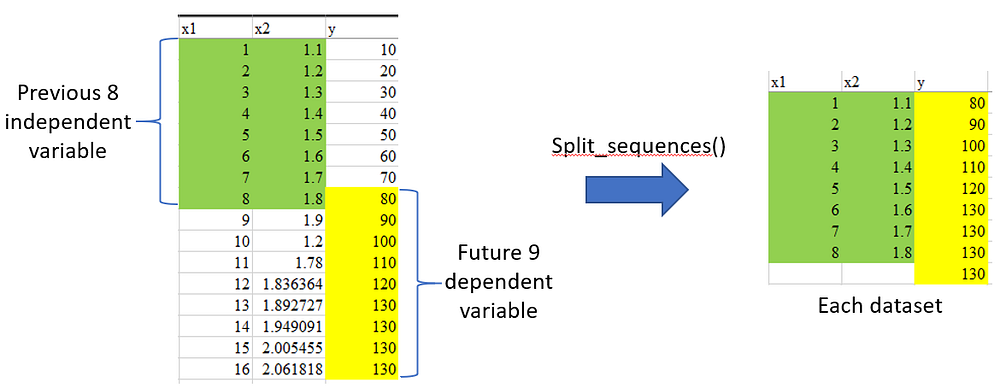
Let’s get started, shall we?
We will be using the famous air pollution dataset which i will be sharing with you in the end
#Lstm Multivariate Multi-Step
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import pandas as pd
import statsmodels.api as sm
from pandas import DataFrame , concat
from sklearn.metrics import mean_absolute_error , mean_squared_error
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
from numpy import mean , concatenate
from math import sqrt
from pandas import read_csv
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,LSTM,Activation
from sklearn.preprocessing import LabelEncoder
#from keras.models import Sequential
#from keras.layers import Dense
#from keras.layers import LSTM
from numpy import array , hstack
from tensorflow import keras
import tensorflow as tf
dataset = pd.read_csv("pollution.csv", header=0, index_col=0)t = dataset.columns.tolist()
dataset = dataset[['dew', 'temp', 'press', 'wnd_dir', 'wnd_spd', 'snow', 'rain','pollution']]
#else slice is invalid for use in labelEncoder
dataset= dataset.values
# integer encode direction
encoder = LabelEncoder()
dataset[:,3] = encoder.fit_transform(dataset[:,3])
#conver to pd.Dataframe else slices error
dataset = pd.DataFrame(dataset)
dataset.columns = ['dew', 'temp', 'press', 'wnd_dir', 'wnd_spd', 'snow', 'rain','pollution']
Data Pre-processing Step — — — — — — -
#dataset[['dew', 'temp', 'press', 'wnd_dir', 'wnd_spd', 'snow', 'rain','pollution']]
#Data Pre-processing step--------------------------------
x_1 = dataset['dew'].values
x_2 = dataset['temp'].values
x_3 = dataset['press'].values
x_4 = dataset['wnd_spd'].values
x_5 = dataset['wnd_dir'].values
x_6 = dataset['snow'].values
x_7 = dataset['rain'].values
y = dataset['pollution'].values
#x_1 = x_1.values
#x_2 = x_2.values
#y = y.values
# Step 1 : convert to [rows, columns] structure
x_1 = x_1.reshape((len(x_1), 1))
x_2 = x_2.reshape((len(x_2), 1))
x_3 = x_3.reshape((len(x_3), 1))
x_4 = x_4.reshape((len(x_4), 1))
x_5 = x_5.reshape((len(x_5), 1))
x_6 = x_6.reshape((len(x_6), 1))
x_7 = x_7.reshape((len(x_7), 1))
y = y.reshape((len(y), 1))
print ("x_1.shape" , x_1.shape)
print ("x_2.shape" , x_2.shape)
print ("y.shape" , y.shape)
# Step 2 : normalization
scaler = MinMaxScaler(feature_range=(0, 1))
x_1_scaled = scaler.fit_transform(x_1)
x_2_scaled = scaler.fit_transform(x_2)
x_3_scaled = scaler.fit_transform(x_3)
x_4_scaled = scaler.fit_transform(x_4)
x_5_scaled = scaler.fit_transform(x_5)
x_6_scaled = scaler.fit_transform(x_6)
x_7_scaled = scaler.fit_transform(x_7)
y_scaled = scaler.fit_transform(y)
# Step 3 : horizontally stack columns
dataset_stacked = hstack((x_1_scaled, x_2_scaled,x_2_scaled, x_3_scaled,
x_4_scaled, x_5_scaled,x_7_scaled, y_scaled))
print ("dataset_stacked.shape" , dataset_stacked.shape)
#Split the sequence
#1. n_steps_in : Specify how much data we want to look back for prediction
#2. n_step_out : Specify how much multi-step data we want to forecast
# split a multivariate sequence into samples
def split_sequences(sequences, n_steps_in, n_steps_out):
X, y = list(), list()
for i in range(len(sequences)):
# find the end of this pattern
end_ix = i + n_steps_in
out_end_ix = end_ix + n_steps_out-1
# check if we are beyond the dataset
if out_end_ix > len(sequences):
break
# gather input and output parts of the pattern
seq_x, seq_y = sequences[i:end_ix, :-1], sequences[end_ix-1:out_end_ix, -1]
X.append(seq_x)
y.append(seq_y)
return array(X), array(y)
# choose a number of time steps #change this accordingly
n_steps_in, n_steps_out = 60 , 30
# covert into input/output
X, y = split_sequences(dataset_stacked, n_steps_in, n_steps_out)
print ("X.shape" , X.shape)
print ("y.shape" , y.shape)
Do the Train and Test split
# Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
train_X, test_X,train_y, test_y = train_test_split(X, y, test_size = 0.2, random_state = 0)
#split_point = 1258*25
#train_X , train_y = X[:split_point, :] , y[:split_point, :]
#test_X , test_y = X[split_point:, :] , y[split_point:, :]
train_X.shape #[n_datasets,n_steps_in,n_features]
train_y.shape #[n_datasets,n_steps_out]
test_X.shape
test_y.shape
n_features = 7
#number of features
#n_features = 2
#optimizer learning rate
opt = keras.optimizers.Adam(learning_rate=0.0001)
# define model
model = Sequential()
model.add(LSTM(50, activation='relu', return_sequences=True, input_shape=(n_steps_in, n_features)))
model.add(LSTM(50, activation='relu'))
model.add(Dense(n_steps_out))
model.add(Activation('linear'))
model.compile(loss='mse' , optimizer=opt , metrics=['accuracy'])
# Fit network
history = model.fit(train_X , train_y , epochs=1500, steps_per_epoch=25 , verbose=1 ,validation_data=(test_X, test_y) ,shuffle=False)
That's it! we are done… now its time to predict
#TEST DATA----------------------------------------
dataset_test_ok = pd.read_csv('pollution_test_data1.csv')
dataset_test_ok.head()#pre-process the new data into the same input format provided during #training the lstm
# integer encode direction
encoder1 = LabelEncoder()
dataset_test_ok.iloc[:,3] = encoder1.fit_transform(dataset_test_ok.iloc[:,3])
# read test data
x1_test = dataset_test_ok['dew'].values
x2_test = dataset_test_ok['temp'].values
x3_test = dataset_test_ok['press'].values
x4_test = dataset_test_ok['wnd_spd'].values
x5_test = dataset_test_ok['wnd_dir'].values
x6_test = dataset_test_ok['snow'].values
x7_test = dataset_test_ok['rain'].values
y_test = dataset_test_ok['pollution'].values # no need to scale
# convert to [rows, columns] structure
x1_test = x1_test.reshape((len(x1_test), 1))
x2_test = x2_test.reshape((len(x2_test), 1))
x3_test = x3_test.reshape((len(x3_test), 1))
x4_test = x4_test.reshape((len(x4_test), 1))
x5_test = x5_test.reshape((len(x5_test), 1))
x6_test = x6_test.reshape((len(x6_test), 1))
x7_test = x7_test.reshape((len(x7_test), 1))
y_test = y_test.reshape((len(y_test), 1))
x1_test_scaled = scaler.fit_transform(x1_test)
x2_test_scaled = scaler.fit_transform(x2_test)
x3_test_scaled = scaler.fit_transform(x3_test)
x4_test_scaled = scaler.fit_transform(x4_test)
x5_test_scaled = scaler.fit_transform(x5_test)
x6_test_scaled = scaler.fit_transform(x6_test)
x7_test_scaled = scaler.fit_transform(x7_test)
# Step 3 : horizontally stack columns
dataset_test_stacked = hstack((x1_test_scaled,x2_test_scaled,x3_test_scaled,x4_test_scaled,
x5_test_scaled,x6_test_scaled,x7_test_scaled))
print ("dataset_stacked.shape" , dataset_test_stacked.shape)Now call the predict function, that's it.
##Prediction#######################################
dataset_test_X = dataset_test_stacked
print("dataset_test_X :",dataset_test_X.shape)
test_X_new = dataset_test_X.reshape(1,dataset_test_X.shape[0],dataset_test_X.shape[1])
y_pred = model.predict(test_X_new)
y_pred_inv = scaler1.inverse_transform(y_pred)
y_pred_inv = y_pred_inv.reshape(n_steps_out,1)
y_pred_inv = y_pred_inv[:,0]
print("y_pred :",y_pred.shape)
print("y_pred_inv :",y_pred_inv.shape)
Congratulations, we can now apply MultiStep MultiVariate LSTM
I tried my best to keep to the point without wasting much time running across. Check out the kaggle implementation:
Explore and run machine learning code with Kaggle Notebooks | Using data from Air Pollution Forecasting - LSTM…www.kaggle.com
Thanks, for your time, if you enjoyed this short article there are tons of topics in advanced analytics, data science, and machine learning available in my medium repo. https://medium.com/@bobrupakroy
Some of my alternative internet presences Facebook, Instagram, Udemy, Blogger, Issuu, Slideshare, Scribd and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Let me know if you need anything. Talk Soon.



Comments
Post a Comment