Auto Keras: Automate your deep learning neural network with 1 line of code
Auto Keras
Automate your deep learning neural network with 1 line of code

Hi there, how are things going on? i hope there are no rough rides.
Today i will bring to the latest automation process for the Artificial Neural Neural Network (ANN).
As we are aware of ANN or any other deep-learning neural networks are time-consuming to hyper-tune with the optimal parameter settings as they include a lot of parameters.
So to make our life easier and focus more on delivering actionable intelligence rather than coding iterations for optimal parameter settings, i bring you here the AUTO KERAS
Let's understand this with the hands-on implementation.
#autokeras - CLASSIFICATION
# load the sonar dataset
from pandas import read_csv
from numpy import asarray
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/sonar.csv'
dataframe = read_csv(url, header=None)
print(dataframe.shape)
# split into input and output elements
data = dataframe.values
X, y = data[:, :-1], data[:, -1]
print(X.shape, y.shape)
# basic data preparation
X = X.astype('float32')
y = LabelEncoder().fit_transform(y)
# separate into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
Till here we are good? the same old stuffs. from data loading to preprocessing and the train test split.
Now, we will AutoKeras to automatically discover an effective neural network model for our data
#import autokeras
from autokeras import StructuredDataClassifier
# define the search
search = StructuredDataClassifier(max_trials=100)
#try out with lower values as it takes considerable amount of time
# perform the search
search.fit(x=X_train, y=y_train, verbose=1)
# evaluate the model
loss, acc = search.evaluate(X_test, y_test, verbose=1)
print('Accuracy: %.3f' % acc)
as per the documentation default max_trials is 100. the more the better to the limit where the auto early stoping function will help to retain the best possible value.
The StructuredDataClassifier official repo. link https://autokeras.com/tutorial/structured_data_regression/
Now let's predict
# use the model to make a prediction
row = [0.0200,0.0371,0.0428,0.0207,0.0954,0.0986,0.1539,0.1601,0.3109,0.2111,0.1609,0.1582,0.2238,0.0645,0.0660,0.2273,0.3100,0.2999,0.5078,0.4797,0.5783,0.5071,0.4328,0.5550,0.6711,0.6415,0.7104,0.8080,0.6791,0.3857,0.1307,0.2604,0.5121,0.7547,0.8537,0.8507,0.6692,0.6097,0.4943,0.2744,0.0510,0.2834,0.2825,0.4256,0.2641,0.1386,0.1051,0.1343,0.0383,0.0324,0.0232,0.0027,0.0065,0.0159,0.0072,0.0167,0.0180,0.0084,0.0090,0.0032]
X_new = asarray([row]).astype('float32')
yhat = search.predict(X_new)
print('Predicted: %.3f' % yhat[0])# get the best performing model
model = search.export_model()
# summarize the loaded model
model.summary()
# save the best performing model to file
model.save('model_sonar.h5')
we can also view the model.summary() just like we do before
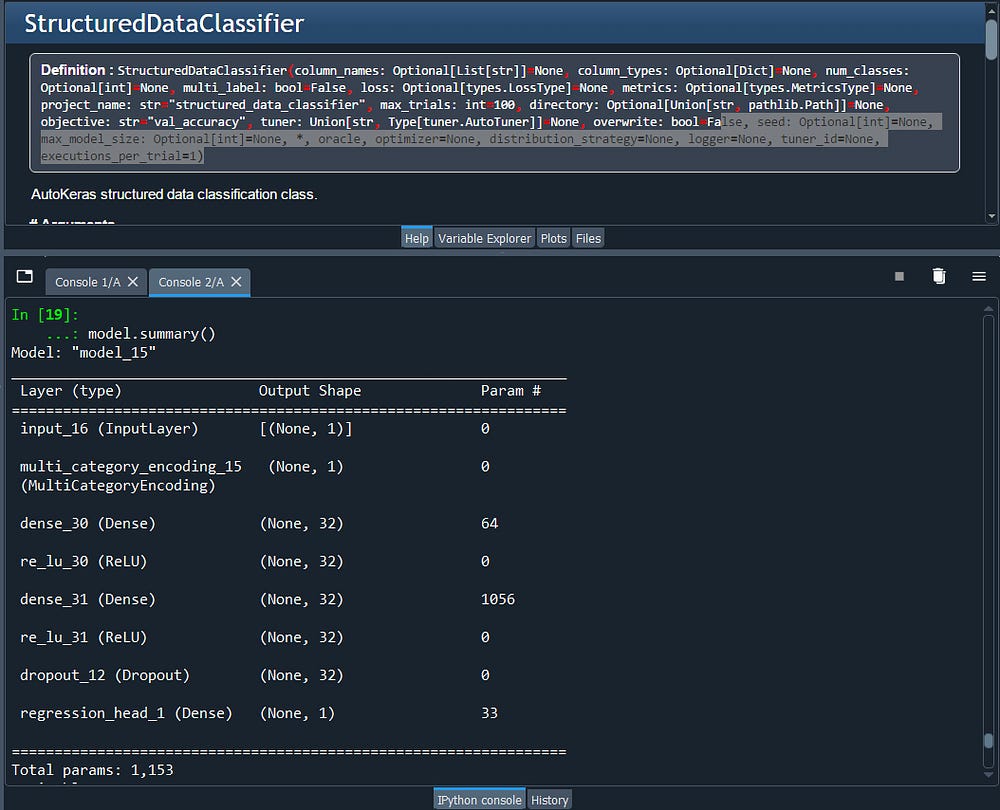
That's it! done
The same way we can do for Regression. let me give me you the snippet.
#AutoKeras for Regression
# use autokeras to find a model for the insurance dataset
from numpy import asarray
from pandas import read_csv
from sklearn.model_selection import train_test_split
from autokeras import StructuredDataRegressor
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/auto-insurance.csv'
dataframe = read_csv(url, header=None)
print(dataframe.shape)
# split into input and output elements
data = dataframe.values
data = data.astype('float32')
X, y = data[:, :-1], data[:, -1]
print(X.shape, y.shape)
# separate into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
# define the search
search = StructuredDataRegressor(max_trials=50, loss='mean_absolute_error')
# perform the search
search.fit(x=X_train, y=y_train, verbose=1)
# evaluate the model
mae, _ = search.evaluate(X_test, y_test, verbose=1)
print('MAE: %.3f' % mae)
# use the model to make a prediction
X_new = asarray([[108]]).astype('float32')
yhat = search.predict(X_new)
print('Predicted: %.3f' % yhat[0])
# get the best performing model
model = search.export_model()
# summarize the loaded model
model.summary()
# save the best performing model to file
model.save('model_insurance.h5')
The official Repo: https://autokeras.com/tutorial/structured_data_regression/
Lovely isn’t.
Thanks, for your time, if you enjoyed this short article there are tons of topics in advanced analytics, data science, and machine learning available in my medium repo. https://medium.com/@bobrupakroy
Some of my alternative internet presences Facebook, Instagram, Udemy, Blogger, Issuu, Slideshare, Scribd and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Let me know if you need anything. Talk Soon.



Comments
Post a Comment