Auto Evaluate Feature Selection: Providing us to evaluate the accuracy of the important feature.
Auto Evaluate Feature Selection
Providing us to evaluate the accuracy of the important feature.

Hello there, how’s life. I hope it's doing great? likewise today i will introduce you to a new feature selection process using Bregman Divergence
What is Bregman divergence?
In statistics, divergence is a function that establishes the “distance” between two probability distributions. In other words, it measures the difference between two distributions. If we interpret these two distributions as a set of observable values, we can measure the distance between them. Bregman divergence is one of many divergences.
It can be calculated with the squared Euclidean distance:
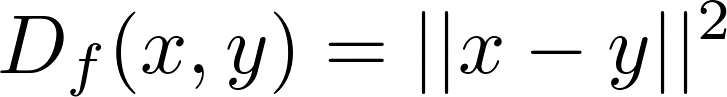
We can select features in a dataset based on the divergence between them and the target. That is what BregmanDivergenceSelector does
Before we go hands-on with the algorithm, I have put all of them into one packing saying that it will not only give the feature importance as well help us to understand the accuracy of any model using the important features without any extra coding effort.
What is ItakuraSaitoSelector?
Again, it's a selector based on Itakura-Saito divergence, which measures the difference between an original spectrum and an approximation of it. The spectrum can be thought of as a continuous distribution.
How is it calculated?
Itakura-Saito divergence is a Bregman divergence generated by the minus logarithmic function. It can be calculated with the following formula:
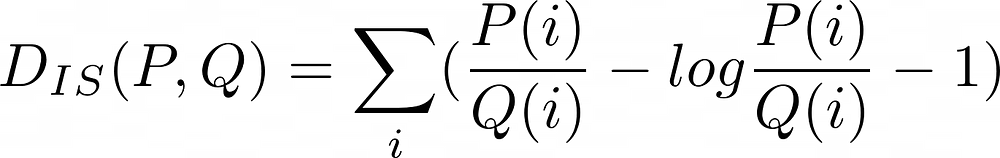
where p and q are the distributions.
Shall we get started?
For this demo, we will use a simple kaggle heart health status dataset
Available at: https://www.kaggle.com/rupakroy/heart-analysis
Currently, we need to manually install the packages, i will be adding them to the package dependencies list for auto-download and installation
#pip install sklearn==1.0.1
#pip install kydavra==0.3.1
Now load the dataset
import pandas as pd
df = pd.read_csv('heart.csv')
#select numeric data types or convert it
df = df.select_dtypes('number')
df.head()
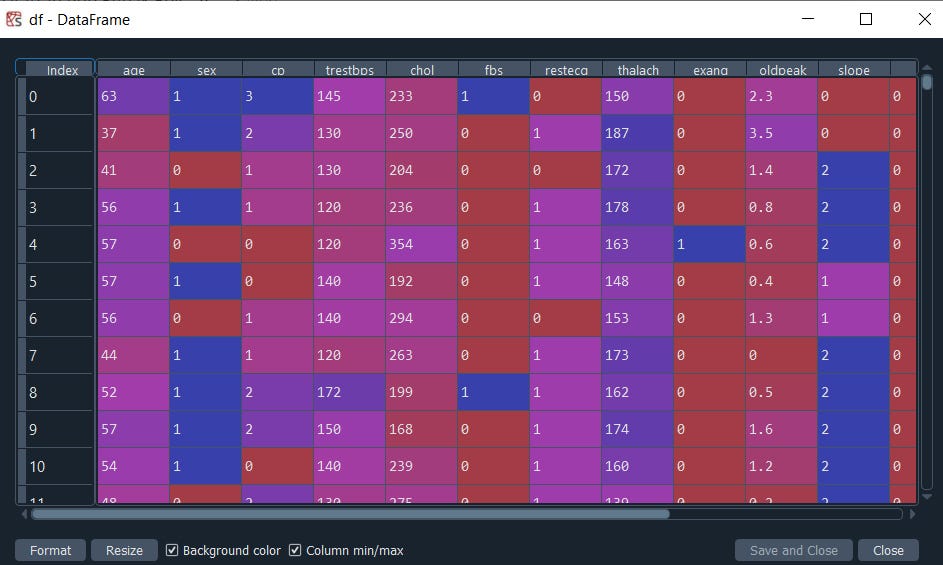
Time to install our package
pip install auto-feat-selection==0.0.8
#import the package
from auto_feat_select_rupakbob import auto_feat_selection
#Get the important features list
#index 0 = BregmanDivergenceSelector, index 1 = ItakuraSaitoSelector
cols_BregmanDivergenceSelector = auto_feat_selection.grid_feat_search(df,'target',5)[0]
cols_ItakuraSaitoSelector = auto_feat_selection.grid_feat_search(df,'target',5)[1]
Output: The important Features [‘sex’, ‘cp’, ‘fbs’, ‘restecg’, ‘exang’, ‘oldpeak’, ‘slope’, ‘ca’, ‘thal’]
#grid_feat_search(dataframe, ‘target_column_name’, max_divergence(default = 0,max = 10) accepted divergence with the target column)
min_divergence (int, default: 0): the minimum accepted divergence with the target column
max_divergence (int, default: 10): the maximum accepted divergence with the target column
EVALUATE
auto_feat_selection.evaluate_grid_feat_search(df,cols_BregmanDivergenceSelector,target ='target')
auto_feat_selection.evaluate_grid_feat_search(df,cols_ItakuraSaitoSelector,target ='target')
###Currently supports Logistic Regression & Random Forest base model with goal to evaluate feature performance
#evaluate_grid_feat_search(dataframe,’taget_column_name’)
Output:
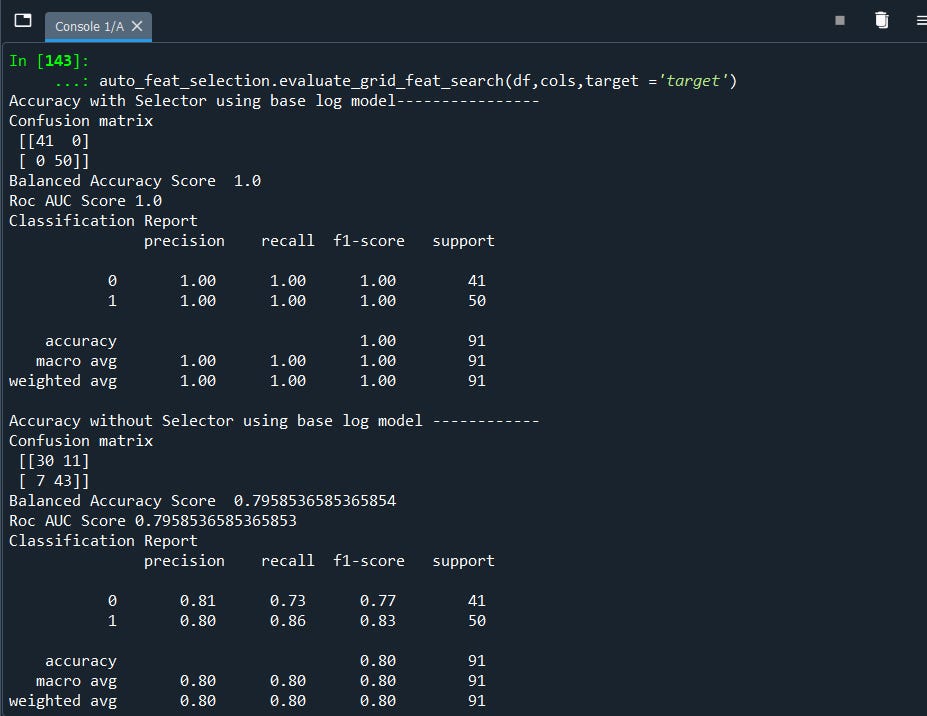
auto_feat_selection.evaluate_grid_feat_search(df,cols,target ='target')That's it! we can clearly see the difference. With and without the important features.
I hope you enjoyed it. I tried to keep the article short and straightforward to the point. I hope the package will be useful at some point in your work. Because I believe machine learning is not replacing us, it's about replacing the same iterative work that consumes time and much effort. So I believe people should come to the work to create innovations rather than be occupied in the same repetitive boring tasks.
Thanks again, for your time, if you enjoyed this short article there are tons of topics in advanced analytics, data science, and machine learning available in my medium repo. https://medium.com/@bobrupakroy
Some of my alternative internet presences Facebook, Instagram, Udemy, Blogger, Issuu, Slideshare, Scribd and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Let me know if you need anything. Talk Soon.
Package repo: https://pypi.org/project/auto-feat-selection/0.0.8/
Kaggle implementation: https://www.kaggle.com/rupakroy/auto-feature-selection-using-bregman-divergence/notebook



Comments
Post a Comment