Auto Clustering - Hacked version for auto clustering with optimized K

Hi everyone, how are you doing? i hope it is good. Today i found an amazing hack to automate the find of the optimal number of K for Kmeans clustering.
Before if you remember we use Elbow Method via visualization and guessed the optimal number of K? and the drawback is we cant automate that and extract the optimal K value for Kmeans.
i was lucky enough through a rigorous web search to find a way to automate the process and put it in a pypi package for you.
Before we get started let’s take a famous common dataset ‘crime_dataset.csv’ or any as per your choice and carry on with our traditional way using Elbow Method.
The Crime Dataset already provides the number of cluster values along with it, will help us to cross-validate if our AutoElbow is able to find the same optimal number of K.
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('crime_data.csv')
#drop the missing values
dataset = dataset.dropna()
#droping the pre-existing cluster values
X = dataset.iloc[:,2:].values
#Normalization
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X=sc_X.fit_transform(X)
#spliting is not required(optional for later validation purpose)
from sklearn.model_selection import train_test_split
X_train, X_test = train_test_split(X, test_size = 0.2, random_state = 0)
#Using the elbow method to find the optimal number of clusters
from sklearn.cluster import KMeans
wcss = []
for i in range(1, 11):
kmeans = KMeans(n_clusters = i, init = 'k-means++', random_state = 0)
kmeans.fit(X_train)
wcss.append(kmeans.inertia_)
plt.plot(range(1, 11), wcss)
plt.title('The Elbow Method')
plt.xlabel('Number of clusters')
plt.ylabel('WCSS')
plt.show()
![crime_dataset before X = dataset.iloc[:,2:].values](https://cdn-images-1.medium.com/max/1000/1*8ii4p8P3IP8IfCHIRxWSfw.jpeg)
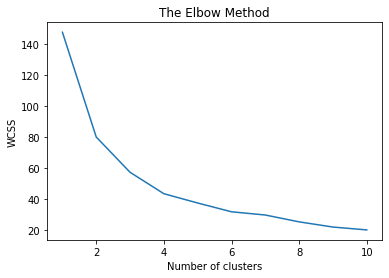
So according to our original dataset and the elbow method, the optimal number of clusters is 4. now let's see if we can get the same via AutoElbow package that i have put together for you.
#pip install autoelbow
from autoelbow_rupakbob import autoelbow
n =autoelbow.auto_elbow_search(X)
And we have n = 4 that exactly matches with the original number of clusters!
For the rest, we can continue the same
# Fitting K-Means to the dataset
kmeans_model = KMeans(n_clusters =n, init = 'k-means++', random_state = 0)
#Predicting with new data
y_kmeans = kmeans_model.fit_predict(X_train)
y_kmeans1 = kmeans_model.fit_predict(X_test)
#We can also merge the results: clusters for later analysis
df = pd.DataFrame( X_train, y_kmeans)
#renaming the index column
df.index.name = "cluster"
df
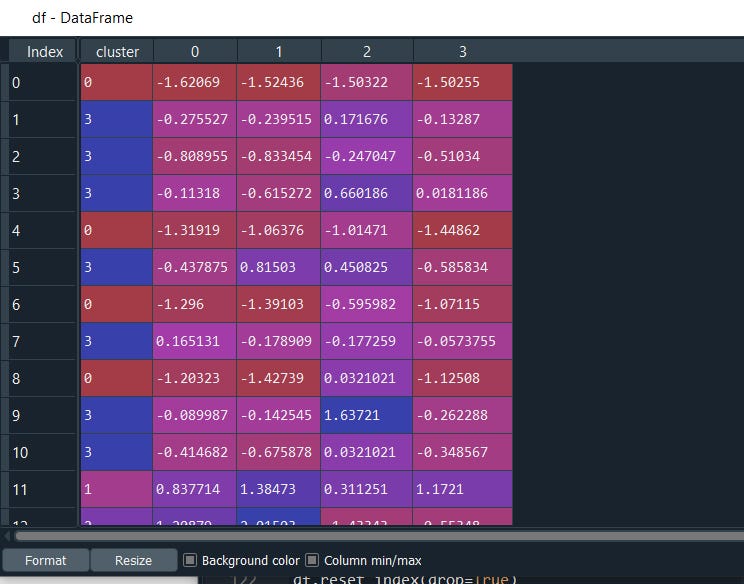
That’s it we can now successfully perform the automation of Kmeans Clustering with just 2 lines of code
from autoelbow_rupakbob import autoelbow
n =autoelbow.auto_elbow_search(X)
Likewise, i hope you enjoyed it.
If you like to know more about advanced types of clustering follow my other article A-Z Clustering
Some of my alternative internet presences are Facebook, Instagram, Udemy, Blogger, Issuu, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Have a good day.



Comments
Post a Comment