ThymeBoost - An ensemble boosting approach for time series sequential learning

Hi everyone, how are things going on? just like before today I am happy to present you something new in the field of sequential data learning a.k.a. Time Series.
As you have already seen I have stopped running around taking detours of meaning and definitions for the topic. Si let’s make this topic short, simple and straight forward.
Have a new new boosting approach to take care of sequential learning and it seems to be quite powerful.
The approach is named as “ThymeBoost”.
According to the documentation
“ThymeBoost combines time series decomposition with gradient boosting to provide a flexible mix-and-match time series framework for spicy forecasting. At the most granular level are the trend/level (going forward this is just referred to as ‘trend’) models, seasonal models, and endogenous models. These are used to approximate the respective components at each ‘boosting round’ and sequential rounds are fit on residuals in usual boosting fashion.”
Basic flow of the algorithm:
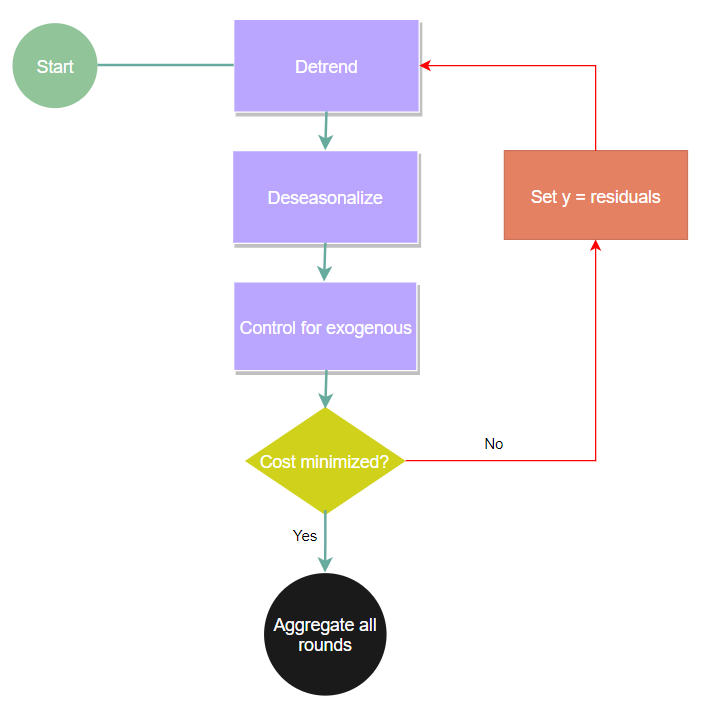
To get started, install thymeboost using
pip install ThymeBoostwe will use the famous ‘AirPassenger.csv’ dataset across few other Time series algrithims to compare the performances.
Let’s get started.
import numpy as np
import pandas as pd
import searborn as sns
sns.set_style("darkgrid")
from matplotlib import pyplot as plt
from ThymeBoost import ThymeBoost as tb
#load the dataset
df = pd.read_csv('AirPassengers.csv')
df.index = pd.to_datetime(df['Month'])
y = df['Passengers']
#we will split the dataset into train and test
test_len = int(len(y) * 0.3)
al_train, al_test = y.iloc[:-test_len], y.iloc[-test_len:]
We are done with loading and splitting the dataset into train and test for evaluation purpose. Now lets apply thymeboost
boosted_model = tb.ThymeBoost(verbose=0)
output = boosted_model.autofit(al_train,seasonal_period=12)
predicted_output = boosted_model.predict(output, len(al_test)) #al_test* is the length of the future dataset.
#Here we need to mention the same as test set #so that we can compare the predicted and the actual data
#evaluation metrics
tb_mae = np.mean(np.abs(al_test - predicted_output['predictions']))
tb_rmse = (np.mean((al_test - predicted_output['predictions'])**2))**.5
tb_mape = np.sum(np.abs(predicted_output['predictions'] - al_test)) / (np.sum((np.abs(al_test))))
#to extract the components
predicted_output.predicted_seasonality
predicted_output.predicted_trend
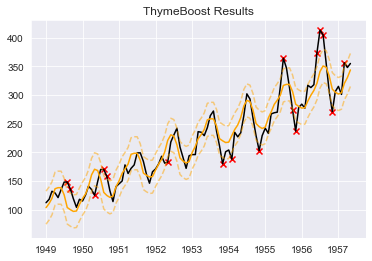
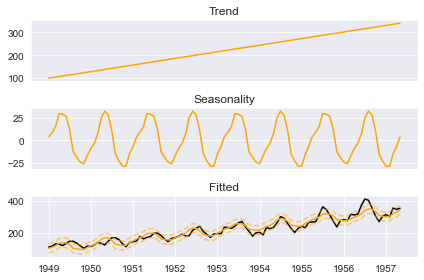
#Plot the components
boosted_model.plot_components(output, predicted_output)
#output* is the original dataset + appended with future dates i.e. predicted_output*
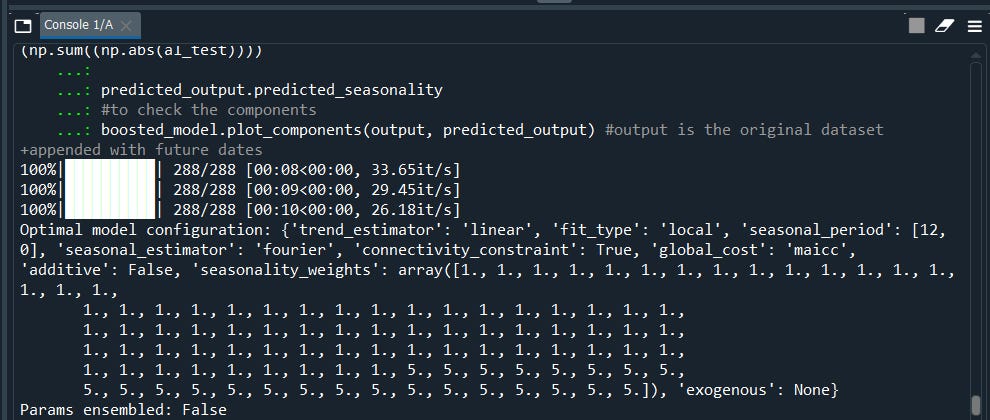
Done!
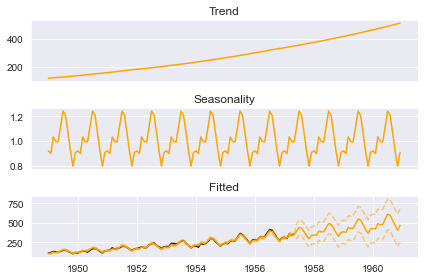
#to extract the components
predicted_output.predicted_seasonality
predicted_output.predicted_trend
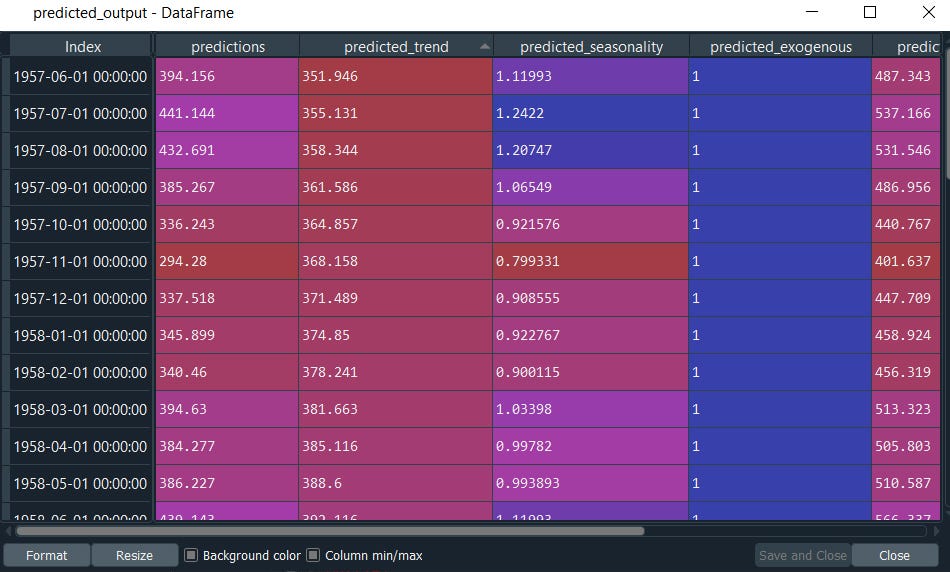
ThymeBoost also can be used for detecting time series anomalies.
Here is it the code snippet.
#detect outliers
boosted_model = tb.ThymeBoost()
output = boosted_model.detect_outliers(al_train,
trend_estimator='linear',
seasonal_estimator='fourier',
seasonal_period=25,
global_cost='maicc',
fit_type='global')
boosted_model.plot_results(output)
boosted_model.plot_components(output)
If you wish to explore more about the usecases of ThymeBoost here’s the official repo link https://pypi.org/project/ThymeBoost/
that's it ! we will take one step further by comparing with other popular time series algorithms in the market FbProphet and ARMIA
#Auto Arima model
import pmdarima as pm
arima = pm.auto_arima(al_train,
seasonal=True,
m=12,
trace=True,
error_action='warn',
n_fits=50)
pmd_predictions = arima.predict(n_periods=len(al_test))
arima_mae = np.mean(np.abs(al_test - pmd_predictions))
arima_rmse = (np.mean((al_test - pmd_predictions)**2))**.5
arima_mape = np.sum(np.abs(pmd_predictions - al_test)) / (np.sum((np.abs(al_test))))
#Fbprophet
from fbprophet import Prophet
prophet_train_df = al_train.reset_index()
prophet_train_df.columns = ['ds', 'y']
prophet = Prophet(seasonality_mode='multiplicative')
prophet.fit(prophet_train_df)
future_df = prophet.make_future_dataframe(periods=len(al_test), freq='M')
prophet_forecast = prophet.predict(future_df)
prophet_predictions = prophet_forecast['yhat'].iloc[-len(al_test):]
prophet_mae = np.mean(np.abs(al_test - prophet_predictions.values))
prophet_rmse = (np.mean((al_test - prophet_predictions.values)**2))**.5
prophet_mape = np.sum(np.abs(prophet_predictions.values - al_test)) / (np.sum((np.abs(al_test))))
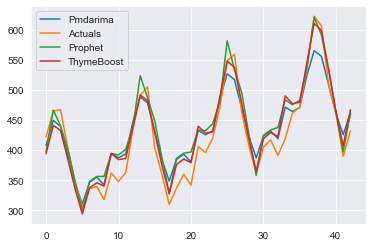
Let’s sum up the numbers
# Creating a dictionary
d = {'mae': [tb_mae,arima_mae,prophet_mae],
'rmse': [tb_rmse,arima_rmse,prophet_rmse],
'mape': [tb_mape,arima_mape,prophet_mape]}
performance = pd.DataFrame(d,index=["ThymeBoost","Arima","Fbprophet"])
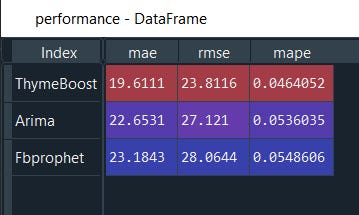
Clearly we can see ThymeBoost is the winner over all the evaluation metrics.
I hope you enjoyed and find the article was useful?
Likewise bringing you the best of many worlds… enjoy!
Feel Free to ask because “Curiosity Leads To Perfection”
Some of my alternative internet presences are Facebook, Instagram, Udemy, Blogger, Issuu, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Stay tuned for more updates.! have a good day….
~ Be Happy and Enjoy, Talk soon.



Comments
Post a Comment