Synthetic Data Vault — Time Series, Probabilistic AutoRegressive model, A deep learning approach to generate synthetic for time series data

Hi there, i hope you enjoyed my previous article on how to generate synthetic tabular data. This time we will take the same approach for Sequential Data i.e. Time Series data. So for this, we will use a dedicated model called as PAR- Probabilistic AutoRegressive model
PAR allows learning multi-type, multivariate time-series data and later on generate new synthetic data that has the same format and properties as the original one.
let’s quickly go over the implementation
#install the package
pip install sdv
#load the data
from sdv.demo import load_timeseries_demo
data = load_timeseries_demo()
data.head()
Before we get started with the modeling we need to define some parameters of the model as follows:
#Entity Columns
#These are columns that indicate how the rows are associated with external,
entity_columns = ['Symbol']
#Context Columns
#variables that provide information about the entities associated #with the timeseries in the form of attributes and which may #condition how the timeseries variables evolve.
context_columns = ['MarketCap', 'Sector', 'Industry']
#The Date column
sequence_index = 'Date'
The rest of the columns of the dataset we will treat them as data columns where the PAR model will learn to generate sequential synthetic data conditioned on the values of the context_columns.
from sdv.timeseries import PAR
model = PAR(entity_columns=entity_columns,context_columns=context_columns,
sequence_index=sequence_index)
model.fit(data)
Once we have fit the model we can generate the sample data just like before by calling model.sample
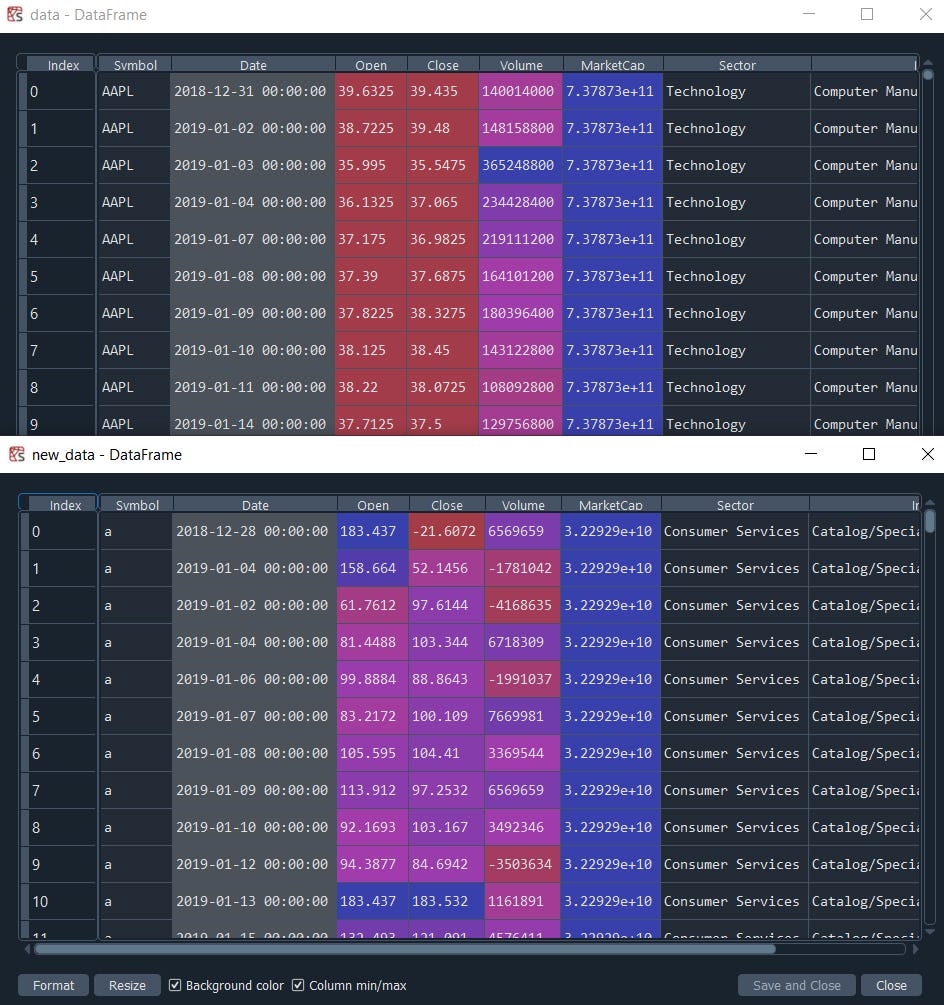
new_data = model.sample(1)
This will return an identical table to the original one.
#save the model
model.save('my_model.pkl')
#load the model
loaded = PAR.load('my_model.pkl')
new_data = loaded.sample(num_sequences=1).head()
and just like before we can save and load the model and export it from production systems to the local systems for further usage.
But there are some cases when we wish to control the values of the contextual columns like to force the model into generating a certain data type.
Let’s see how can we do that
#generate values for two companies in the Technology and Health Care sectors.
import pandas as pd
context = pd.DataFrame([{'Symbol': 'AAAA','MarketCap': 1.2345e+11,'Sector': 'Technology','Industry': 'Electronic Components'},
{'Symbol': 'BBBB','MarketCap': 4.5678e+10,'Sector': 'Health Care',
'Industry': 'Medical/Nursing Services'},])context
Now simply pass the dataframe in the context parameter to the method model.sample()
new_data = model.sample(context=context)
that's it!
I hope you enjoy it again simple yet powerful.
Read the article:
https://blogs.nvidia.com/blog/2021/06/08/what-is-synthetic-data/
Next, we will look into how to evaluate our models on how accurately our model is able to preserve the characteristics of the dataframe.
Oh ya in our next article I will put the link of the repo just in case if you wish to go into detail and explore more of its advantage.
Some of my alternative internet presences Facebook, Instagram, Udemy, Blogger, Issuu, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Have a good day.



Comments
Post a Comment