Synthetic Data Evaluation* Compare the synthetic data generated with its origin.

Hey there, WhatsUp! finally, we are close to the end of the synthetic data topic.
As we have seen in our previous articles the ways from classical to deep learning approaches to create synthetic data. Today we will discuss how to evaluate them based on their real data.
let’s get started quickly, it has already been a long journey.
#load the dataset, in our case we can use the built-in demo dataset
from sdv.metrics.demos import load_single_table_demo
real_data, synthetic_data, metadata = load_single_table_demo()
the metadata is the dictionary representation of the student_placements metadata will look somewhat like this
{'fields': {'start_date': {'type': 'datetime', 'format': '%Y-%m-%d'},
'end_date': {'type': 'datetime', 'format': '%Y-%m-%d'},
'salary': {'type': 'numerical', 'subtype': 'integer'},
'duration': {'type': 'categorical'},
'student_id': {'type': 'id', 'subtype': 'integer'},
'high_perc': {'type': 'numerical', 'subtype': 'float'},
'high_spec': {'type': 'categorical'},
'mba_spec': {'type': 'categorical'},
'second_perc': {'type': 'numerical', 'subtype': 'float'},
'gender': {'type': 'categorical'},
'degree_perc': {'type': 'numerical', 'subtype': 'float'},
'placed': {'type': 'boolean'},
'experience_years': {'type': 'numerical', 'subtype': 'float'},
'employability_perc': {'type': 'numerical', 'subtype': 'float'},
'mba_perc': {'type': 'numerical', 'subtype': 'float'},
'work_experience': {'type': 'boolean'},
'degree_type': {'type': 'categorical'}},
'constraints': [],
'model_kwargs': {},
'name': None,
'primary_key': 'student_id',
'sequence_index': None,
'entity_columns': [],
'context_columns': []}Now further this evaluation is divided into a few different ways to evaluate.
- Statistical Metrics: compares the table by running a different statistical test
from sdv.metrics.tabular import CSTest, KSTest
#KSTest: This metric uses the two-sample Kolmogorov–Smirnov test to #compare the distributions of continuous columns using the empirical #CDF
'''The output for each column is 1 minus the KS Test D statistic, which indicates the maximum distance between the expected CDF and the observed CDF values.'''
KSTest.compute(real_data, synthetic_data)
#CSTest: uses Chi-Squared test to compare the distributions of two #discrete columns, the output will be in p-value which is the probability of two columns having been sampled from the
#sample distribution.
CSTest.compute(real_data, synthetic_data)
we can do KSTest and CSTest it in one shot using evaluate
from sdv.evaluation import evaluate
evaluate(synthetic_data, real_data, metrics=['CSTest', 'KSTest'], aggregate=False)
2. Likelihood Metrics
#pip install pomegranate to run the below packages
from sdv.metrics.tabular import BNLikelihood, BNLogLikelihood, GMLogLikelihood
#this metric fits a BayesiaNetwork to the real data and then #evaluates the average likelihood of the rows from the synthetic #data on it.
BNLikelihood.compute(real_data.fillna(0), synthetic_data.fillna(0))
#the same as above but here we taking log into consideration, so it #will be the average log likelihood
raw_score1 = BNLogLikelihood.compute(real_data.fillna(0), synthetic_data.fillna(0))
#This metric will use GaussianMixture addition to average log #likelihood
raw_score2 = GMLogLikelihood.compute(real_data.fillna(0), synthetic_data.fillna(0))
#we can normalize our results between 0 and 1 by simply using the #normalize method instead of using the likelihood scores
BNLogLikelihood.normalize(raw_score1)
3. Detection Metrics: tries to distinguish how hard it is the synthetic data from the real data using the machine-learning model.
The output will be in 1 minus the average ROC AUC score across all the cross-validation splits
from sdv.metrics.tabular import LogisticDetection, SVCDetection
LogisticDetection.compute(real_data, synthetic_data)
SVCDetection.compute(real_data, synthetic_data)
4. Machine Learning Efficacy Metrics: These metrics will evaluate whether it is possible to replace the real data with synthetic data in order to solve a Machine Learning Problem by learning a Machine Learning model on the synthetic data and then evaluating the score which it obtains when evaluated on the real data.
from sdv.metrics.tabular import MulticlassDecisionTreeClassifier
MulticlassDecisionTreeClassifier.compute(real_data, synthetic_data, target='mba_spec')
The output value does not only depend on how good our synthetic data is, but also on how hard the machine learning problem that we are trying to solve is. For instance, we may also compare each model's results with real data and synthetic data.
5. Privacy Metrics: These metrics measure the privacy of the synthetic dataset identical to the real data. The models accomplish this by fitting an adversarial attacker model on the synthetic data to predict sensitive attributes from “key” attributes and then evaluating its accuracy on the real data.
#the metrics do not accept missing values, so we will replace or #drop for this example
real_data = real_data.fillna(0)
real_data.isna().sum()
from sdv.metrics.tabular import NumericalLR
NumericalLR.compute(real_data,synthetic_data,key_fields=['second_perc', 'mba_perc', 'degree_perc'],
sensitive_fields=['salary'])
The output range will be between 0 and 1 where the closer the value is to 0 the less private it is.
That's it! I hope you enjoyed the article, i tried my best to replicate and make it simpler with my intuition to bring more innovative solutions from across.
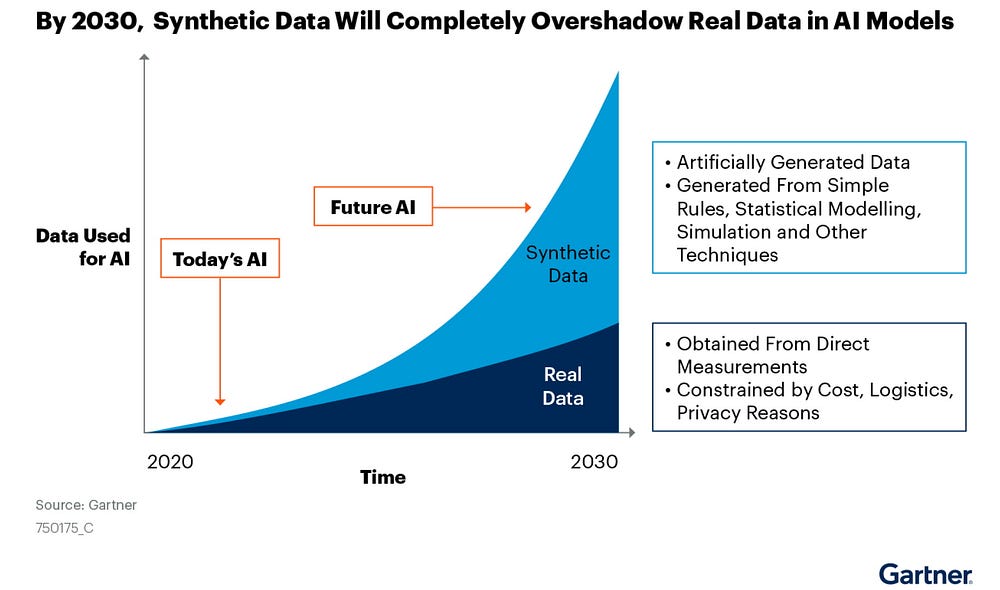
Read the article:
https://blogs.nvidia.com/blog/2021/06/08/what-is-synthetic-data/
Next, we have the evaluation metrics from Synthetically generated time-series data and also i will be sharing with you the repo of the package for in-detail documentation. So see you there in our next final chapter of Synthetic Data Vault.
Some of my alternative internet presences Facebook, Instagram, Udemy, Blogger, Issuu, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Have a good day.



Comments
Post a Comment