VAE-based Deep Learning data synthesizer ~ TVAE, Synthetic Data Vault — IV, Triplet-based Variable AutoEncoders, A deep learning approach for building synthetic data.

Hi, hey there congratulations for reaching out here, it has been a long way by various deep learning approaches of data synthesizers, this will be our last article on that and later we will move ahead with the evaluation metrics.
Let’s get started likewise we will keep it short and simple to be less irritating.
TVAE model is based on the VAE Variable AutoEncoders or we can say Triplet based Variable AutoEncoders
The model was first presented at the NeurlPS 2020 conference by the paper titled Modeling Tabular data using Conditional GAN.
Now let’s quickly discover how to generate synthetic data using TVAE
#first we need to install the package
pip install sdv
#load a sample dataset
from sdv.demo import load_tabular_demo
data = load_tabular_demo('student_placements')
data.head()
Let us use the TVAE to learn the sample data and then generate a synthetic dataset capturing the characteristics of the sample dataset above.
from sdv.tabular import TVAE
model = TVAE()
model.fit(data)
Now to generate new synthetic data all we need to do is call the sample.method from the model passing the number of rows that we want to generate.
new_data = model.sample(200)
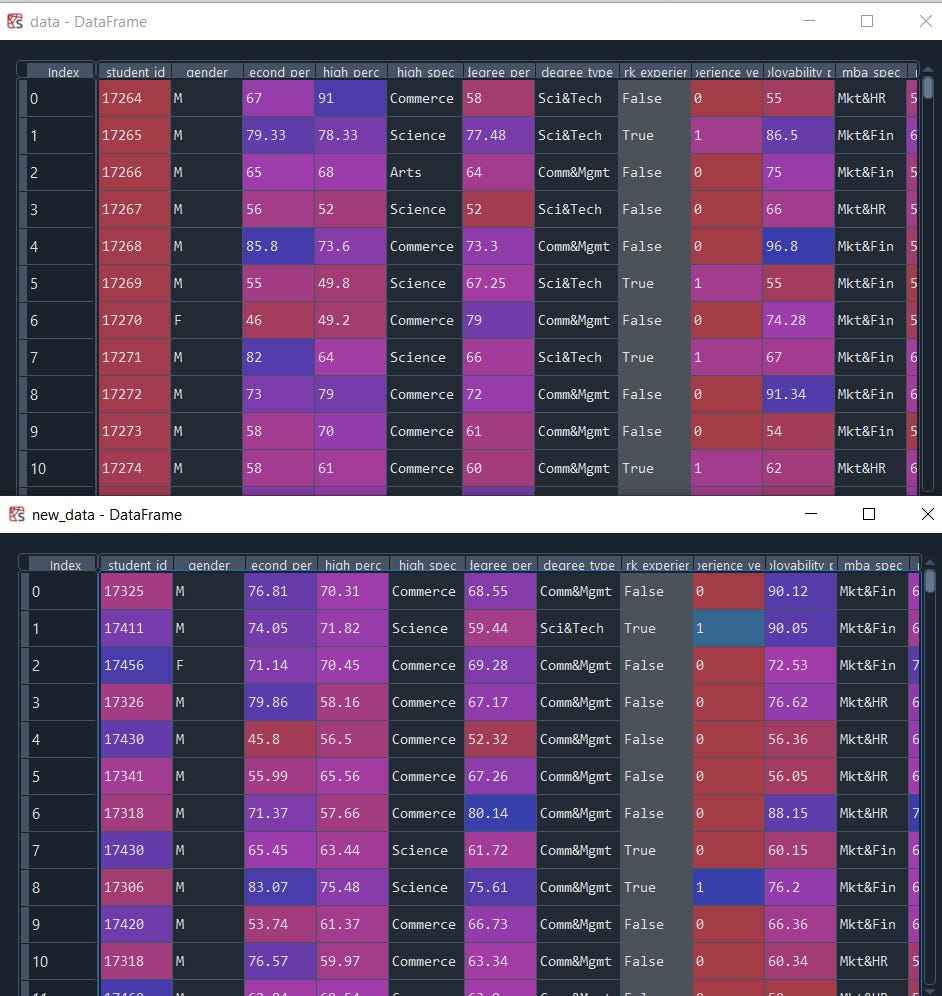
We can observe identical data to the original table. Finally, save and share the model will be convenient to generate a synthetic version of your data directly in systems that do not have access to the original data source.
#save the model
model.save('my_model.pkl')
Load back the model with CTGAN load and start generating new sample data identical to the original one.
#load the model
loaded = TVAE.load('my_model.pkl')
new_data = loaded.sample(200)
One of the important things u might have missed if you have checked the student_id column which needs to be unique and in our synthetic data we have generated some values more than once.
The way to fix this is to define the unique value column as a ‘primary key’ in our model.
model = TVAE(primary_key='student_id')
model.fit(data)
new_data = model.sample(200)
Anonymizing Personally Identifiable Information (PII)
There are some situations where the data will contain personally identifiable information which cannot disclose. Thus we will replace the information with simulated data that looks similar to the real one but doesn’t contain the original values.
data_pii = load_tabular_demo('student_placements_pii')
data_pii.head()model = TVAE(primary_key='student_id',anonymize_fields={'address': 'address' })model.fit(data_pii)
new_data_pii = model.sample(200)
new_data_pii.head()
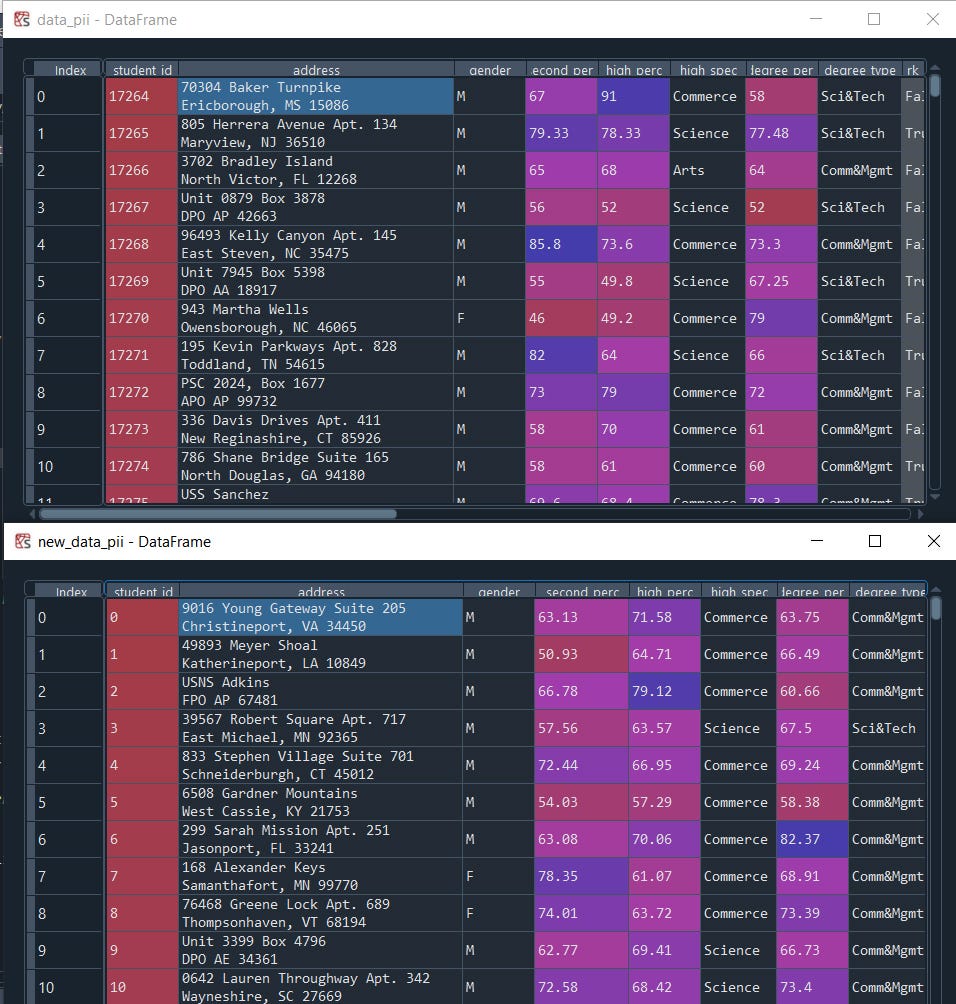
That’s it, just use one parameter anonymize_fields we can clearly see the difference.
you might also notice if you read my previous article this article is kind of self-repeating with a different algorithm, the reason is we have a couple of more approaches and want to make it quick and simple with a goal to make you deliver you the best algorithms across.
I hope you enjoyed it,
Read the article:
https://blogs.nvidia.com/blog/2021/06/08/what-is-synthetic-data/
Likewise, I will try my best to bring more new ways of Data Science.
Next, we will see how to evaluate our synthetic data generated by the models that we did so far in the next article. see ya!
Some of my alternative internet presences Facebook, Instagram, Udemy, Blogger, Issuu, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Have a good day.



Comments
Post a Comment