Synthetic Minority Oversampling Technique ~SMOTE

We might have encountered our target variable classes imbalanced. One of the best examples is a Fraudulent transaction where we can observe the proportion of fraudulent transactions is less as compared to others. Thus when we train the model it will misclassify and will tend to predict more of the other classes rather than the Fraudulent Classes. The reason behind this makes sense because we have trained the model with fraudulent transaction records lesser than the other transactions.
To cover this issue, we will create Synthetic Data of the minority class. The 2 commonly used methods are
1. SMOTE (Synthetic Minority Oversampling Technique) — Oversampling
2. Near Miss Algorithm
Let's start with SMOTE the most commonly used method
SMOTE (Synthetic Minority Oversampling Technique) aims to balance class distribution by replicating the minority class.
SMOTE tries to harness the power of K-nearest neighbors to replicate and generate the synthetic data.
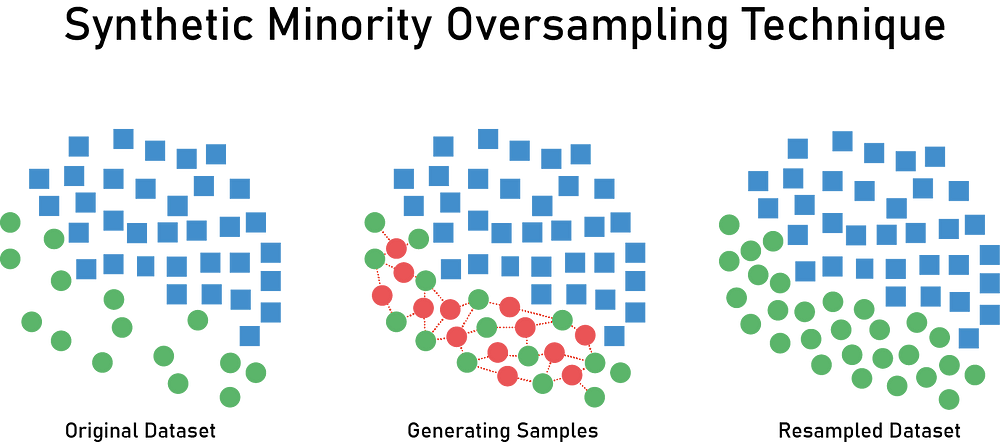
There are also different variants of SMOTE like Borderline SMOTE, Adaptive Synthetic Sampling (ADASYN) which we will discuss later.
First, let’s get started with SMOTE — OverSampling
#Frist we will build a baseline model for comparison
# import necessary modules
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, classification_report
# load the data set
data = pd.read_csv('creditcard.csv')
X = data.drop("Class",axis=1)
y = data["Class"]# as you can see there are 492 fraud transactions.
data['Class'].value_counts()
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 0)
# logistic regression object
lr = LogisticRegression()
lr.fit(X_train, y_train.ravel())
predictions = lr.predict(X_test)
#print classification report
print(classification_report(y_test, predictions))
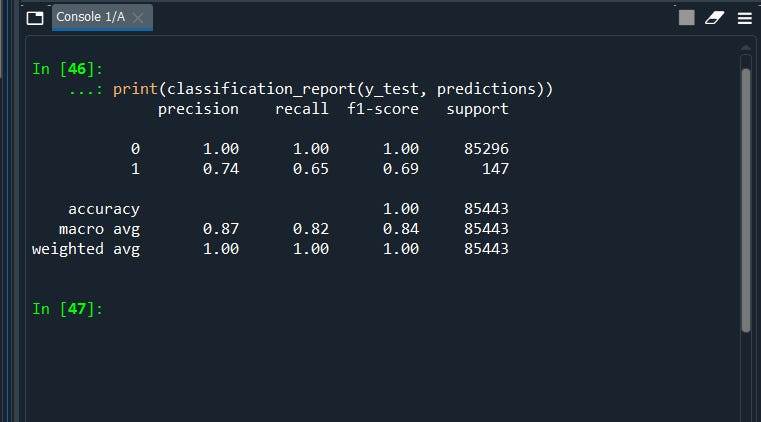
Now re-run the model with SMOTE
print("Before OverSampling, counts of label '1': {}".format(sum(y_train == 1)))
print("Before OverSampling, counts of label '0': {} \n".format(sum(y_train == 0)))Before OverSampling, counts of label ‘1’: 345
Before OverSampling, counts of label ‘0’: 199019
#pip install imbalanced-learn
from imblearn.over_sampling import SMOTE
sm = SMOTE(sampling_strategy=1,random_state = 2)
X_train_res, y_train_res = sm.fit_resample(X_train, y_train.ravel())
#sampling_strategy 1 refers 100% i.e. 50:50
print("After OverSampling, counts of label '1': {}".format(sum(y_train_res == 1)))
print("After OverSampling, counts of label '0': {}".format(sum(y_train_res == 0)))After OverSampling, counts of label ‘1’: 199019
After OverSampling, counts of label ‘0’: 199019
Here we go! we have our classes balanced
lr1 = LogisticRegression()
lr1.fit(X_train_res, y_train_res.ravel())
predictions = lr1.predict(X_test)
# print classification report
print(classification_report(y_test, predictions))
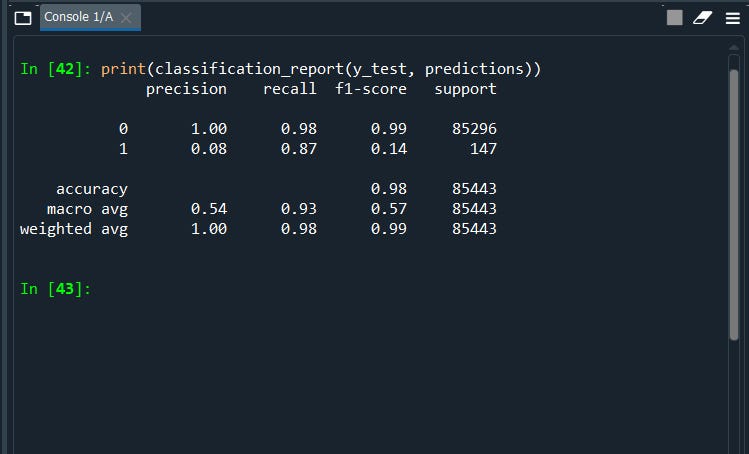
Notice, we have now better recall accuracy from our previous model. Thus this is a good model as compared to our previous model.
Next we look into its variants Borderline SMOTE and Adaptive Synthetic Sampling (ADASYN) but in my next article. wanna keep the article short and clean. Here is the link below
https://bobrupakroy.medium.com/1d74756fb049?source=friends_link&sk=5e85614647ded5689ae9d74bc32d3380
See you there!
Some of my alternative internet presences are Facebook, Instagram, Udemy, Blogger, Issuu, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Have a good day.



Comments
Post a Comment