Isolation Forest. Full Guide To The Best Outlier Treatment Approach

Hi everyone, how’s everything? good and great? Today I will introduce you to one of the most powerful anomaly/outlier detection methods called Isolation Forest.
Shall we get started?
What is an isolation forest?
Isolation forest is an unsupervised learning algorithm that works on the principle of isolating anomalies. Isolation Forest like any other tree ensemble method is built on the basis of the decision tree. Just a Random Forest here in Isolation Forest we are isolating the extreme values.
Extreme values are less frequent than regular observations i.e. they lie further from the regular observations in the feature space. Thus with random sub-sampling/bootstrap aggregating like in the random forest, isolation forest is able to identify and isolate the extreme values.
Here are some pictorial representations of isolation forest
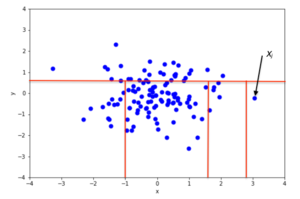
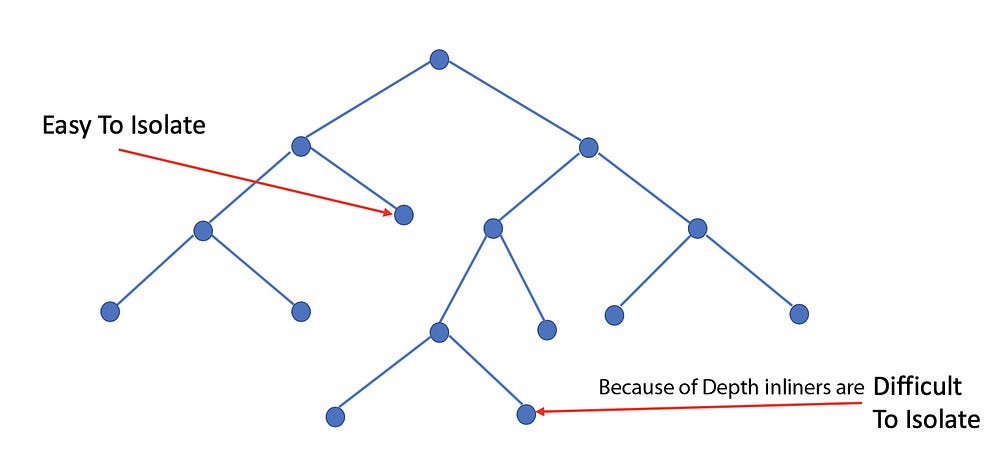
It isolates the extreme values by randomly selecting a feature from the given set of features and then randomly selecting a split value between the max and min values of that feature. This random partitioning of features will produce shorter paths in trees thus distinguishing them from the rest of the data.
Let’s see how we can perform that.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import IsolationForest
from sklearn.metrics import mean_absolute_error
df = pd.read_csv("housing.csv")
data = df.values#define the X and y
X, y = data[:, :-1], data[:, -1]
# split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
Above is our regular data loading and splitting the data set into train and test.
# identify outliers in the training dataset
iso = IsolationForest(contamination=0.1)
yhat = iso.fit_predict(X_train)
np.unique(yhat)
#Filter out/select all rows that are not outliers
mask = yhat != -1
X_train, y_train = X_train[mask, :], y_train[mask]
#Else impute the outliers with nan then replace with mean or median
#mask = yhat ==-1
#Impute with nan
#-----replace with mean or median----
that’s it, we have our dataset cleaned. You can explore its parameters for more stricter fine-tuned rule
IsolationForest(*, self, n_estimators=100, max_samples="auto", contamination="auto", max_features=1., bootstrap=False, n_jobs=None, behaviour='deprecated', random_state=None, verbose=0, warm_start=False)
n_estimators = 100(default)
The number of base estimators in the ensemble.
contamination = “auto”(default) The proportion of outliers in the data set. Used when fitting to define the threshold on the scores of the samples.
Now we can carry forward our cleaned dataset for any modeling tasks
from sklearn.model_selection import KFold, cross_val_score
kfold =KFold(n_splits=3)
#no. of base classifiers
num_trees = 500
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import BaggingRegressor
#bagging classifier
model_regressor = BaggingRegressor(base_estimator = DecisionTreeRegressor(),n_estimators=num_trees,random_state=3)
results1 =cross_val_score(model_regressor,X_train,y_train,cv = kfold)
results1.mean()
model_regressor.fit(X_train,y_train)
model_regressor.predict(X_test)
# evaluate the model
yhat = model_regressor.predict(X_test)
# evaluate predictions
mae = mean_absolute_error(y_test, yhat)
print('MAE: %.3f' % mae)
Well, I have added 2 accuracy checkpoints… K-fold Cross_validation_score and Mean Absolute Error (MAE)
Done….!
Do Remember Isolation Forest has performed on Train ‘X’ dataset that is excluding of target ‘y’ dataset.
Next, we have another interesting outlier treatment algorithm called “OneClassSVM” interested? keep in touch
See you soon…..
Some of my alternative internet presences are Facebook, Instagram, Udemy, Blogger, Issuu, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Have a good day.



Comments
Post a Comment