Extra Trees Classifier / Regressor. A Powerful Alternative Random Forest Ensemble Approach

Hi everyone, today we will explore another powerful ensemble classifier called as Extra Trees Classifier / Regressor
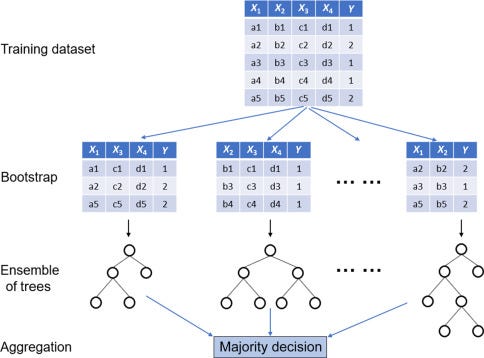
It is a type of ensemble learning technique that aggregates the results of different de-correlated decision trees similar to Random Forest Classifier.
Extra Tree can often achieve a good or better performance than the random forest. The key difference between Random Forest and Extra Tree Classifier is,
- Extra Tree Classifier does not perform bootstrap aggregation like in the random forest. In simple words, takes a random subset of data without replacement. Thus nodes are split on random splits and not on best splits.
- So in Extra Tree Classifier randomness doesn’t come from bootstrap aggregating but comes from the random splits of the data.
If you wish to know more about Bagging /Bootstrap aggregating works you can follow my previous article https://bobrupakroy.medium.com/bagging-classifier-609a3bce7fb3
So to make the Long Story Short.
Decision Tree — are prune to overfitting, thus giving High Variance.
Random Forest — to overcome the Decision Tree problems Random Forest was introduced. Thus gives Medium Variance.
Extra Tree — when accuracy is more important than a generalized model. Thus gives Low Variance
And one more thing — it also gives feature importance’s
Now Let’s see how can we perform it!
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#load the data
url = "Wine_data.csv"
dataframe=pd.read_csv(url)
X= dataframe.drop("quality",axis=1)
y = dataframe["quality"]Let’s consider the data as this demonstration
from sklearn.ensemble import ExtraTreesRegressor
# Building the model
extra_tree_model = ExtraTreesRegressor(n_estimators = 100,
criterion ='mse', max_features = "auto")
# Training the model
extra_tree_model.fit(X, y)
Done…! just like a regular classifier.
We can also perform feature important using the extra_tree_forest.feature_importances_
# Computing the importance of each feature
#Feature Importance
feature_importance = extra_tree_model.feature_importances_
# Plotting a Bar Graph to compare the models
plt.bar(X.columns, feature_importance)
plt.xlabel('Feature Labels')
plt.ylabel('Feature Importances')
plt.title('Comparison of different Feature Importances')
plt.show()
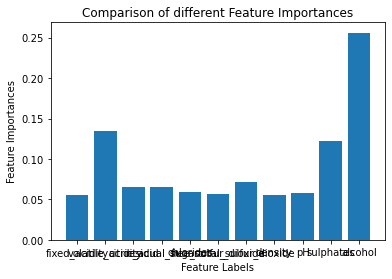
Sorry for the names of the features! overlapping each other.
Let’s do the same for Classification
from sklearn.ensemble import ExtraTreesClassifier
dataframe1 = dataframe.copy()
#Convert the target into a Boolean
dataframe1["quality"] = np.where(dataframe['quality']>=5,1,0)
X= dataframe.drop("quality",axis=1)
y = dataframe["quality"]Now we do the same as before but this time criterion will be ‘entropy’
# Building the model
extra_tree_forest = ExtraTreesClassifier(n_estimators = 100,
criterion ='entropy', max_features = "auto")
# Training the model
extra_tree_forest.fit(X, y)
That’s it!
THE END — — — — — — —
BUT if you find this article useful…. do browse my other ensemble techniques like Bagging Classifier, Voting Classifier, Stacking, and more I guarantee you will like them too. See you soon with another interesting topic.
Some of my alternative internet presences are Facebook, Instagram, Udemy, Blogger, Issuu, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Have a good day.



Comments
Post a Comment