Boosting Classifier / Regressor. Full Guide to Adaptive Sequential Ensemble with meta-estimator

Shall we start our Adaptive Boosting Adventure?
Just like Bagging, Boosting is another class of ensemble machine learning algorithms that combines the predictions from many weak learners
The key difference between Bagging and Boosting is
Bagging works in parallel just like a random forest and based on the voting majority you get the winner output. Here we will more concentrate on Boosting to keep the LONG STORY SHORT. if you want to know more about bagging ensembles here is my article link for more in-detail https://bobrupakroy.medium.com/bagging-classifier-609a3bce7fb3
The WEAK LEARNERS — let me explain to you what is it!
Assume you have an image where 3 times it looks like a cat and 2 times a dog. Now if we have to classify the image with a single judgment it will be dubious which we can call WEAK LEARNERS…..So we will take the total 5 judgments, combine the prediction from each of these weak learners by using the majority rule or weight average to make sure that our prediction is more accurate. In our case out of 5 weak learners, we have 3 as cats and 2 as dogs. That’s it….. our final confirmed output is a CAT.
Boosting follows the same style instead of going through Parallel it will go through Sequence, here the weak learners are sequentially produced and the performance gets improved by assigning a higher weightage to previous incorrectly classified samples. The Best Example is AdaBoost
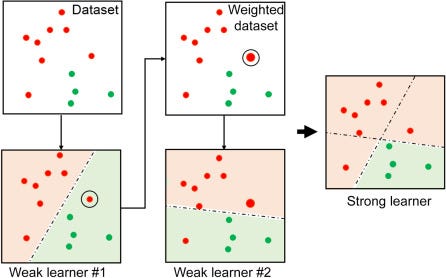
Sounds all clear now? Let’s get started with hands-on experience.
First, we will try with Classification:
import pandas as pd
import numpy as np
#load the data
url = "Wine_data.csv"
dataframe=pd.read_csv(url)
dataframe1 = dataframe.copy()
dataframe1["quality"] = np.where(dataframe['quality']>=5,1,0)
arr = dataframe1.values
X = arr[:, 1:11]
Y = arr[:, 11]
from sklearn.ensemble import AdaBoostClassifier
# define the model
model = AdaBoostClassifier()
#model.fit(X,Y)
from sklearn.model_selection import cross_val_score,KFold
kfold = KFold(n_splits=10)
results = cross_val_score(model,X,Y,cv = kfold)
results.mean()
Here will use a simple AdaBoostClassifier() without a meta-base estimator. If None, then the base estimator is DecisionTreeClassifier initialized with max_depth=1.
There are a few more parameters to choose from
AdaBoostClassifier(*, self, base_estimator=None, n_estimators=50, learning_rate=1., algorithm='SAMME.R', random_state=None)
n_estimators refers the number of base_estimators we will use to ensemble.
algorithm = If ‘SAMME.R’ then use the SAMME.R real boosting algorithm. base_estimator must support calculation of class probabilities. If ‘SAMME’ then use the SAMME discrete boosting algorithm. The SAMME.R algorithm typically converges faster than SAMME, achieving a lower test error with fewer boosting iterations.
Now Let’s try with a meta-base estimator.
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import RandomForestClassifier
# define the model with base_estimator = Random Forest
model = AdaBoostClassifier(RandomForestClassifier())
from sklearn.model_selection import cross_val_score,KFold
kfold = KFold(n_splits=10)
results = cross_val_score(model,X,Y,cv = kfold)
results.mean()
WITH Support Vector Machine SVM
# define the model with base_estimator = SVC
from sklearn.svm import SVC
model = AdaBoostClassifier(SVC(probability=True, kernel='linear'))
from sklearn.model_selection import cross_val_score,KFold
kfold = KFold(n_splits=10)
results = cross_val_score(model,X,Y,cv = kfold)
results.mean()
if we don't use the probability = True, will throw an error. You can also try with SGDClassifier
#define the model with base_estimator = SGDClassifier
from sklearn.linear_model import SGDClassifier
model= AdaBoostClassifier(SGDClassifier(loss='hinge'), algorithm='SAMME')
from sklearn.model_selection import cross_val_score,KFold
kfold = KFold(n_splits=10)
results = cross_val_score(model,X,Y,cv = kfold)
results.mean()
Done….! Try boosting with your favorite algorithm.
For Regression:
url = "Wine_data.csv"
dataframe=pd.read_csv(url)
X= dataframe.drop("quality",axis=1)
Y = dataframe["quality"]from sklearn.ensemble import AdaBoostRegressor
# define the model
model = AdaBoostRegressor()
from sklearn.model_selection import cross_val_score,KFold
kfold = KFold(n_splits=10)
results = cross_val_score(model,X,Y,cv = kfold,scoring='neg_mean_absolute_error')
results.mean()
Here again, we use a simple AdaBoostRegressor() without a meta-base estimator. If None, then the base estimator is DecisionTreeRegressor initialized with max_depth=1.
The same follows like before
from sklearn.ensemble import AdaBoostRegressor
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBRegressor
from sklearn.svm import SVR
# define the model with base_estimator = SVR
model = AdaBoostRegressor(SVR(kernel='linear'))
from sklearn.model_selection import cross_val_score,KFold
kfold = KFold(n_splits=10)
results = cross_val_score(model,X,Y,cv = kfold)
results.mean()
model = AdaBoostRegressor(RandomForestRegressor())
from sklearn.model_selection import cross_val_score,KFold
kfold = KFold(n_splits=10)
results = cross_val_score(model,X,Y,cv = kfold)
results.mean()
model = AdaBoostRegressor(XGBRegressor())
from sklearn.model_selection import cross_val_score,KFold
kfold = KFold(n_splits=10)
results = cross_val_score(model,X,Y,cv = kfold)
results.mean()
from sklearn.linear_model import SGDRegressor
model= AdaBoostRegressor(SGDRegressor())
from sklearn.model_selection import cross_val_score,KFold
kfold = KFold(n_splits=10)
results = cross_val_score(model,X,Y,cv = kfold)
results.mean()
That’s it we are good to go!
I hope you enjoyed it.. see you soon with another cool topic.
If you like to know more about advanced topics like clustering follow my other article ‘A-Z clustering’
Some of my alternative internet presences are Facebook, Instagram, Udemy, Blogger, Issuu, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Have a good day.



Comments
Post a Comment