Create Ensemble Methods in 3 lines of code. Combine the power of Stacking and Voting Classifiers for a high accuracy prediction.

Hi there how are you doing today? great? thanks for the continuous support. Today I show you 2 interesting ways to increase the power of your model.
Yes! it's Ensembling via 1.) Stacking and 2.) Voting Classifier
I will try to keep it short and simple focusing mainly on the core part of the topic.
Let’s begin with Stacking.
What is Stacking?
In short, is an ensemble machine learning algorithm. It involves combining the predictions from multiple machine learning models on the same dataset, like bagging and boosting.
How Stacking is different from bagging and boosting?
Stacking learns to combine the base models using a meta-model whereas bagging and boosting combine weak learners following deterministic algorithms.
Stacking learns them in parallel and combines them by training a meta-model to output a prediction based on the different weak model's predictions
The architecture of a stacking model.
- Level-0 Models (Base-Models): Models fit on the training data and whose predictions are compiled.
- Level-1 Model (Meta-Model): Model that learns how to best combine the predictions of the base models.
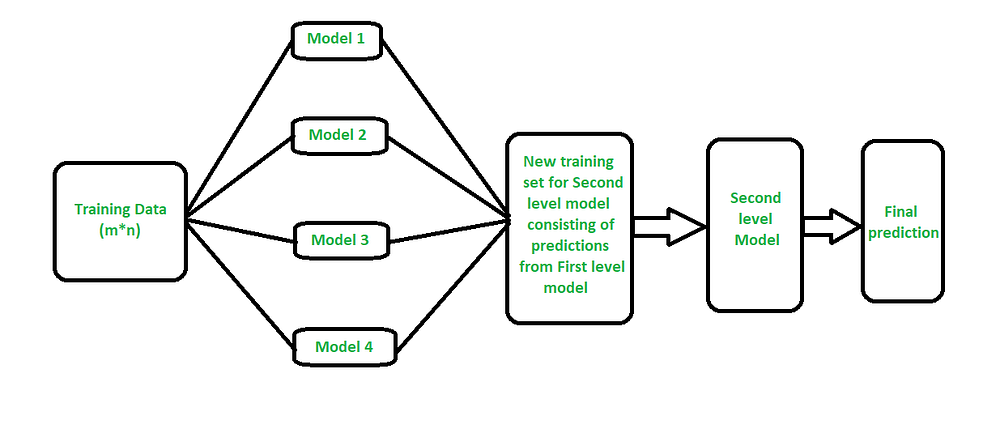
Let’s see how we can perform such.
We will use one of the dataset available in Kaggle Credit Card Dataset.
from numpy import mean
from numpy import std
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedKFold
from sklearn.linear_model import LinearRegression
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import StackingRegressor
from matplotlib import pyplot
import pandas as pd
#loading dataset
dataset = pd.read_csv("credit_data.csv",sep=",")
dataset.isna().sum()
dataset = dataset.dropna()
from collections import Counter
Counter(dataset)
X = dataset.iloc[:,1:4].values
y = dataset.iloc[:,4].values
Above are our regular data loading and basic data pre-processing as well focus more on building the stacking model.
#function to build the list of stacking of models
def get_stacking():
#define base models
level0 = list()
level0.append(('knn',KNeighborsRegressor()))
level0.append(('cart',DecisionTreeRegressor()))
level0.append(('svm',SVR()))
level0.append(('random forest',RandomForestRegressor()))
#define meta leaner model
level1 = LinearRegression()
#define the stacking ensemble
model = StackingRegressor(estimators=level0, final_estimator=level1, cv=5)
return model
#function to evaluate
def get_models():
models = dict()
models['knn'] = KNeighborsRegressor()
models['cart'] = DecisionTreeRegressor()
models['svm'] = SVR()
models['random forest'] = RandomForestRegressor()
models['stacking'] = get_stacking()
return models
# evaluate via cross-validation
def evaluate_model(model, X, y):
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1, error_score='raise')
return scores
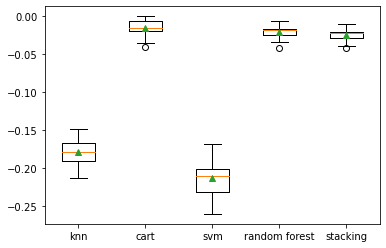
What we got….. seems CART(decision tree model) is performing a little better than the rest. Ya, sometimes a single model performs better than an ensemble. But in our case, we will concentrate on the Stacking of models.
Now let’s re-assemble the previous code to predict unseen data using the Stacking model.
#list of base models
level0 = list()
level0.append(('knn', KNeighborsRegressor()))
level0.append(('cart', DecisionTreeRegressor()))
level0.append(('svm', SVR()))
level0.append(('random forest',RandomForestRegressor()))
# define meta learner model
level1 = LinearRegression()
# define the stacking model
model = StackingRegressor(estimators=level0, final_estimator=level1, cv=5)
#fit the model
model.fit(X, y)
# make a prediction for one example
data = [[0.59332206,-0.56637507,1.34808718]]
yhat = model.predict(data)
print('Predicted Value: %.3f' % (yhat))
Done! The same you can do for Classification, just copy-paste the code and change the Classifiers from Regressor to Classifier() you know that well.
Let me put all the pieces together.
from numpy import mean
from numpy import std
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedKFold
from sklearn.linear_model import LinearRegression
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import StackingRegressor
from matplotlib import pyplot
import pandas as pd
#loading dataset
dataset = pd.read_csv("credit_data.csv",sep=",")
dataset.isna().sum()
dataset = dataset.dropna()
from collections import Counter
Counter(dataset)
X = dataset.iloc[:,1:4].values
y = dataset.iloc[:,4].values
#function to build the list of stacking of models
def get_stacking():
#define base models
level0 = list()
level0.append(('knn',KNeighborsRegressor()))
level0.append(('cart',DecisionTreeRegressor()))
level0.append(('svm',SVR()))
level0.append(('random forest',RandomForestRegressor()))
#define meta leaner model
level1 = LinearRegression()
#define the stacking ensemble
model = StackingRegressor(estimators=level0, final_estimator=level1, cv=5)
return model
#function to evaluate
def get_models():
models = dict()
models['knn'] = KNeighborsRegressor()
models['cart'] = DecisionTreeRegressor()
models['svm'] = SVR()
models['random forest'] = RandomForestRegressor()
models['stacking'] = get_stacking()
return models
# evaluate via cross-validation
def evaluate_model(model, X, y):
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1, error_score='raise')
return scores
#---------Prediction------------------------------
#list of base models
level0 = list()
level0.append(('knn', KNeighborsRegressor()))
level0.append(('cart', DecisionTreeRegressor()))
level0.append(('svm', SVR()))
level0.append(('random forest',RandomForestRegressor()))
# define meta learner model
level1 = LinearRegression()
# define the stacking model
model = StackingRegressor(estimators=level0, final_estimator=level1, cv=5)
#fit the model
model.fit(X, y)
# make a prediction for one example
data = [[0.59332206,-0.56637507,1.34808718]]
yhat = model.predict(data)
print('Predicted Value: %.3f' % (yhat))
Next, We have VOTING CLASSIFIER

What is a Voting Classifier?
Again a machine learning method that simply aggregates the findings of each classifier(models) passed into Voting Classifier and gives the output based on the highest majority of vote of the classifiers(models).
There are two types of voting:
- Hard Voting: here the predicted output with the highest majority of votes is taken into consideration. Example. if the predicted output of the 3 models(svm,knn,rf)are A,A,B then Class A is the winner.
- Soft Voting: here the prediction is based on the average of the probability scores of the classes. Example: if the predicted output(probability scores) of 3 models (svm,knn,rf) are A = (0.40,0.50,0.55) , B = (0.15,0.19,0.23) So the average of Class A will be 0.48 and B is 0.19. Clearly, Class A is the winner.
Moreover or less the impact of using hard voting and soft voting methods in my experience are the same.
Now let’s get started with some hands-on experience.
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# loading iris dataset
iris = load_iris()
X = iris.data[:, :4]
Y = iris.target
# train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, Y,
test_size = 0.20,random_state = 42)
Here the above are the same basic data importing, packages, data pre-processing, test, and train split.
Now, we will create a list of models
# group / ensemble of models
estimator = []
estimator.append(('LR', LogisticRegression(solver ='lbfgs',
multi_class ='multinomial',max_iter = 200)))
estimator.append(('SVC', SVC(gamma ='auto', probability = True)))
estimator.append(('DT', DecisionTreeClassifier()))
estimator.append(('RF',RandomForestClassifier()))
Offcourse we can and need to feed the parameters inside each classifiers(), as of now we will continue with baseline(default) model settings.
1.) Hard Voting
# Voting Classifier with hard voting
vot_hard = VotingClassifier(estimators = estimator, voting ='hard')
vot_hard.fit(X_train, y_train)
y_pred = vot_hard.predict(X_test)
#Accuracy Check
score = accuracy_score(y_test, y_pred)
print("Hard Voting Score % d" % score)
2.) Soft Voting
# Voting Classifier with soft voting
vot_soft = VotingClassifier(estimators = estimator, voting ='soft')
vot_soft.fit(X_train, y_train)
y_pred = vot_soft.predict(X_test)
# using accuracy_score
score = accuracy_score(y_test, y_pred)
print("Soft Voting Score % d" % score)
That’s it, Done!
I hope you find the article was useful.
Bringing you the best of many worlds… enjoy!
Feel Free to ask because “Curiosity Leads To Perfection”
Some of my alternative internet presences are Facebook, Instagram, Udemy, Blogger, Issuu, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Stay tuned for more updates.! have a good day….
~ Be Happy and Enjoy!



Comments
Post a Comment