Bagging Classifier. Transform your regular classifier into a Bagging Classifier in 2 lines of code

Hi, do you know we can transform any of our classifiers into Bagging Classifier like Random Forest for more accuracy? Sounds pretty interesting?
But before we get started let's recap what is Bagging?
Bagging
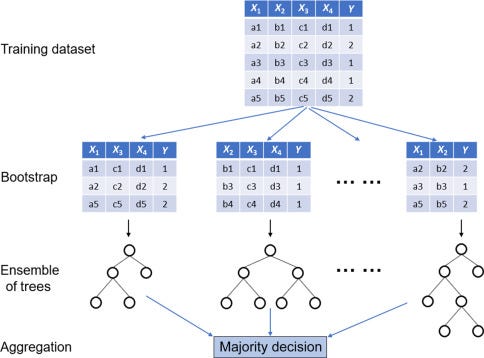
Bagging is also known as Bootstrap aggregating, a machine learning ensemble meta-algorithm designed to improve the stability and accuracy of machine learning algorithms used for classification and regression analysis.
It helps to reduce variance and helps to avoid overfitting. The best example is Random Forest. Bagging is a special case of the model averaging approach
Bagging generates a new random training dataset with replacement. By sampling with replacement, some observations may be repeated in each.
This kind of sample is known as a bootstrap sample. Sampling with replacement ensures each bootstrap is independent of its peers, as it does not depend on previously chosen samples when sampling.
Thus the process of bootstrap sampling helps to reduce variance in the classifier by understanding the pattern of predictions with various random subsets similar to understanding the output for different scenarios. Thus more robust prediction.
Let’s get started,
Regression:
import pandas as pd
import numpy as np
from sklearn import model_selection
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingRegressor
from sklearn.tree import DecisionTreeRegressor
as usual we will load the package from sklearn.ensemble, first we will try with Regression then Classification.
#load the data
url = "Wine_data.csv"
dataframe=pd.read_csv(url)
arr = dataframe.values
X = arr[:, 1:14]
Y = arr[:, 0]
#initialize the base regressor
base_cls = DecisionTreeRegressor()
#split the data
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.2, random_state = 0)
Kfold = model_selection.KFold(n_splits=3)
num_trees = 500
#define bagging regressor
model_reg = BaggingRegressor(base_estimator = base_cls, n_estimators =num_trees,random_state=5)
results = model_selection.cross_val_score(model11,X_train,y_train,cv = kfold)
results.mean()
#We can also use it to predict------------------
#fit the model on the whole dataset
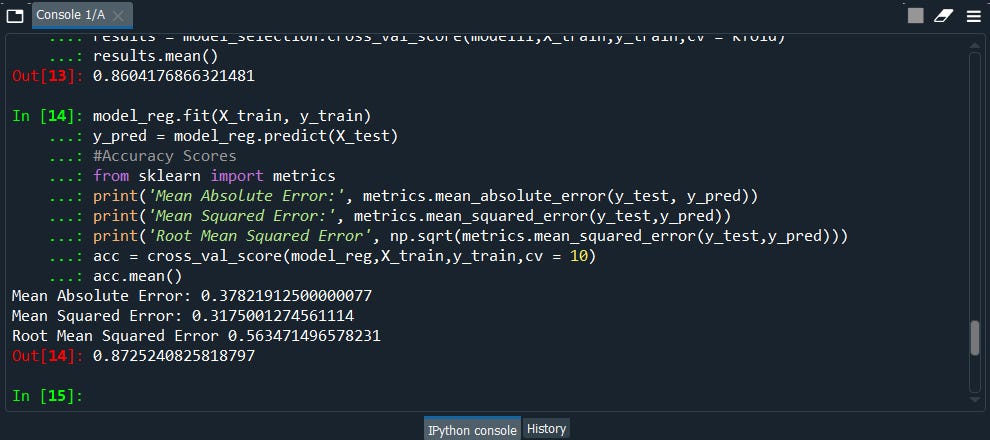
model_reg.fit(X_train, y_train)
y_pred = model_reg.predict(X_test)
#Accuracy Scores
from sklearn import metrics
print('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_pred))
print('Mean Squared Error:', metrics.mean_squared_error(y_test,y_pred))
print('Root Mean Squared Error', np.sqrt(metrics.mean_squared_error(y_test,y_pred)))
acc = cross_val_score(model_reg,X_train,y_train,cv = 10)
acc.mean()
Now Let’s compare the results without the bagging method.
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.2, random_state = 0)
dt_model = DecisionTreeRegressor()
dt_model.fit(X_train,y_train)
y_pred_dt = dt_model.predict(X_test)
from sklearn import metrics
print('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_pred_dt))
print('Mean Squared Error:', metrics.mean_squared_error (y_test,y_pred_dt))print('Root Mean Squared Error', np.sqrt(metrics.mean_squared_error (y_test,y_pred_dt)))acc = cross_val_score(dt_model, X_train,y_train,cv = 10)
acc.mean()
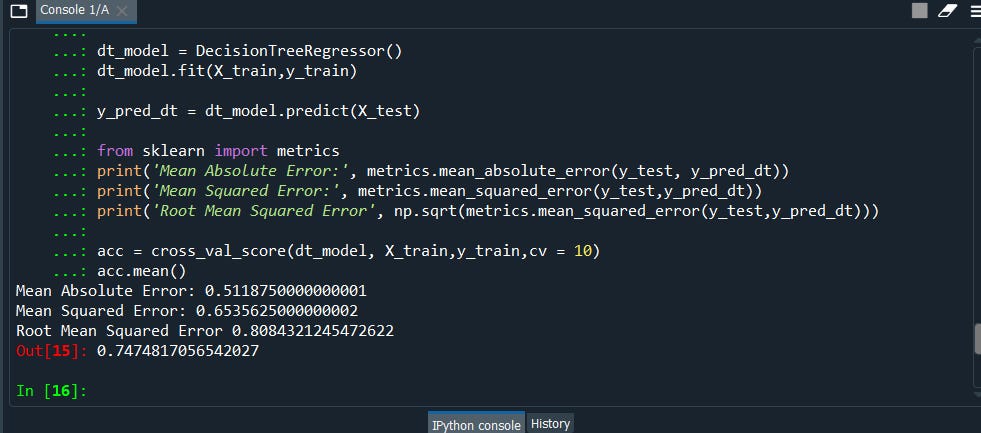
We can clearly see the difference!
Classification
#lets convert the dataset into classification problem
dataframe1 = dataframe.copy()
dataframe1["quality"] = np.where(dataframe['quality']>=5,1,0)
#What we are doing here is converting our previous dataset into a classification problem via if the quality of the wine is equal or more than 5 then it will be class 1(good quality) else class 0(bad quality)
arr = dataframe1.values
X = arr[:, 1:11]
Y = arr[:, 11]
kfold = model_selection.KFold(n_splits=3)
#initialize the base classifier
base_cls = DecisionTreeClassifier()
#no. of base classifiers
num_trees = 500
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.2, random_state = 0)
#bagging classifier
model_classifier = BaggingClassifier(base_estimator = base_cls,n_estimators=num_trees,random_state=3)
results1 = model_selection.cross_val_score(model_classifier,X_train,y_train,cv = kfold)
results1.mean()
# fit the model on the whole dataset
model_classifier.fit(X_train, y_train)
y_pred = model_classifier.predict(X_test)
def evaluation_score (y_test,y_pred):
cm = confusion_matrix(y_test,y_pred)
print("Confusion Matrix \n", cm)
print("Accuracy Score",metrics.accuracy_score(y_test, y_pred))
print('Balanced Accuracy ',metrics.balanced_accuracy_score(y_test,y_pred))
print("Recall Accuracy Score~TP",metrics.recall_score(y_test, y_pred))
print("Precision Score ~ Ratio of TP",metrics.precision_score(y_test, y_pred))
print("F1 Score",metrics.f1_score(y_test, y_pred))
print("auc_roc score", metrics.roc_auc_score(y_test,y_pred))
print("Classification Report \n", metrics.classification_report(y_test,y_pred))
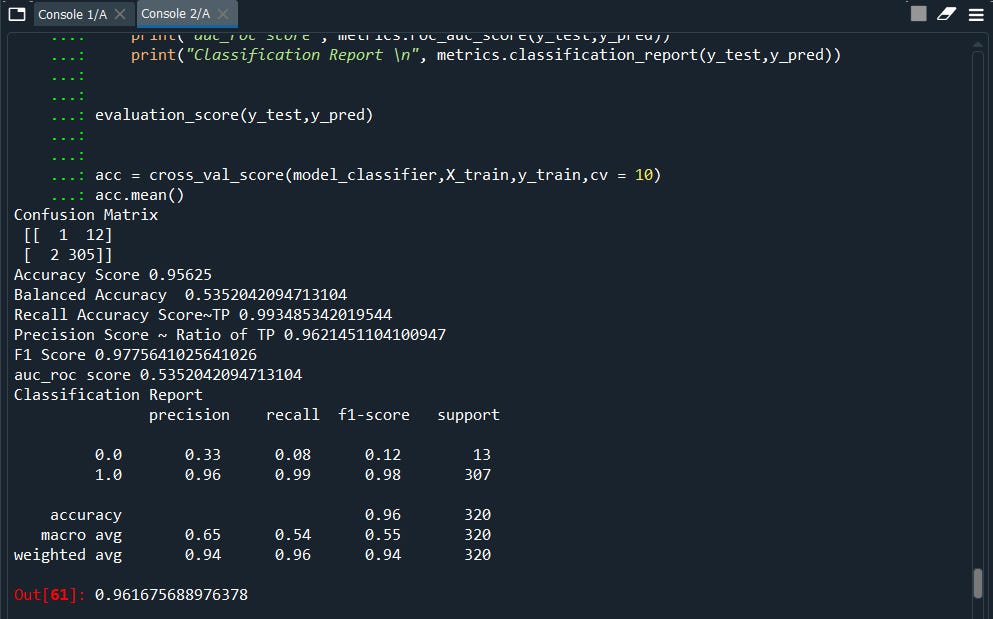
evaluation_score(y_test,y_pred)
acc = cross_val_score(model_classifier,X_train,y_train,cv = 10)
acc.mean()
Now again let’s compare the results without the bagging classifier
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.2, random_state = 0)
dt_model = DecisionTreeClassifier()
dt_model.fit(X_train,y_train)
y_pred_dt = dt_model.predict(X_test)
def evaluation_score (y_test,y_pred):
cm = confusion_matrix(y_test,y_pred)
print("Confusion Matrix \n", cm)
print("Accuracy Score",metrics.accuracy_score(y_test, y_pred))
print('Balanced Accuracy ',metrics.balanced_accuracy_score(y_test,y_pred))
print("Recall Accuracy Score~TP",metrics.recall_score(y_test, y_pred))
print("Precision Score ~ Ratio of TP",metrics.precision_score(y_test, y_pred))
print("F1 Score",metrics.f1_score(y_test, y_pred))
print("auc_roc score", metrics.roc_auc_score(y_test,y_pred))
print("Classification Report \n", metrics.classification_report(y_test,y_pred))
evaluation_score(y_test,y_pred)
acc = cross_val_score(dt_model, X_train,y_train,cv = 10)
acc.mean()
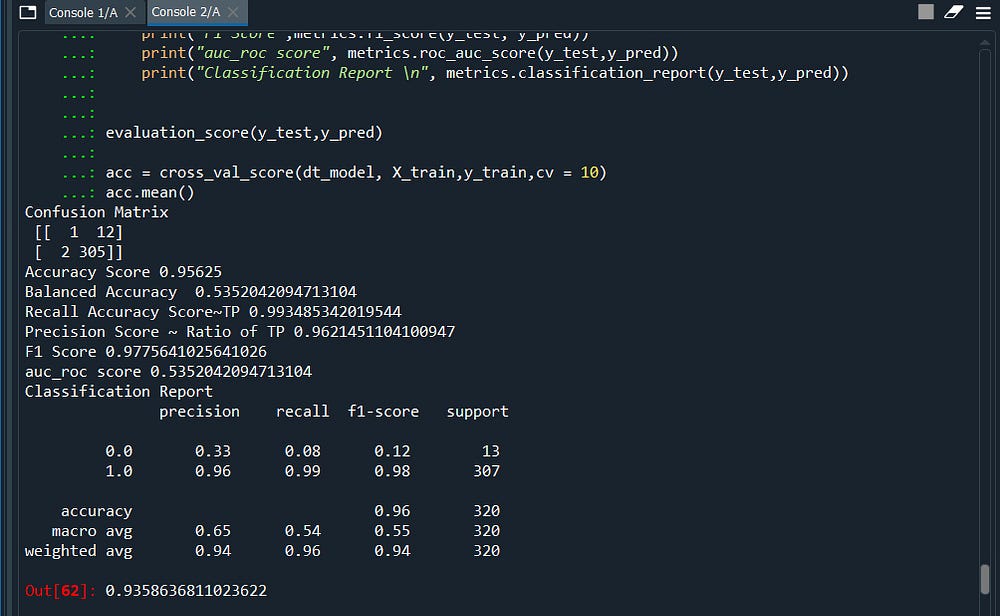
Here we go! we got our winner.
Cool! isn’t it? ……….I hope you enjoyed it.. see you soon with another cool topic.
If you like to know more about advanced topics like clustering follow my other article A-Z Clustering
Some of my alternative internet presences are Facebook, Instagram, Udemy, Blogger, Issuu, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Have a good day.



Comments
Post a Comment